import re
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.ticker as mtick
import matplotlib.patches as mpatches
from math import comb, log, exp, lgamma
from pathlib import Path
plt.rcParams.update({
"figure.dpi": 150,
"axes.spines.top": False,
"axes.spines.right": False,
"font.size": 10,
"axes.titlesize": 12,
"axes.titleweight": "bold",
"figure.facecolor": "#fafafa",
"axes.facecolor": "#fafafa",
})
_DIR = Path(".")
# ── Load IMTS flat file ───────────────────────────────────────────────────────
_CSV = _DIR / "dataset_2026-04-19T01_51_08.510445992Z_DEFAULT_INTEGRATION_IMF.STA_IMTS_1.0.0.csv"
_all_cols = pd.read_csv(_CSV, nrows=0).columns.tolist()
_monthly_cols = [c for c in _all_cols if re.match(r"^\d{4}-M\d{2}$", c)]
_raw = pd.read_csv(_CSV, usecols=["SERIES_CODE"] + _monthly_cols, dtype=str)
_parts = _raw["SERIES_CODE"].str.split(".", n=3, expand=True)
_parts.columns = ["reporter", "indicator", "partner", "freq"]
imts = pd.concat([_parts, _raw[_monthly_cols]], axis=1)
imts = imts[imts["freq"] == "M"].copy()
imts[_monthly_cols] = imts[_monthly_cols].apply(pd.to_numeric, errors="coerce")
# Fix date parsing: "2017-M01" → "2017-01-01"
_dates = pd.to_datetime([c.replace("-M", "-") + "-01" for c in _monthly_cols])
# ── Load ACLED political violence data ────────────────────────────────────────
violence = pd.read_csv(_DIR / "violence_events_long.csv")
violence["date"] = pd.to_datetime(
violence["month"].astype(str) + " " + violence["year"].astype(str),
format="%B %Y"
)Trade as a Signal: Detecting Conflict-Driven Anomalies in IMF Merchandise Trade Data
data
trade
conflict
IMF
IMTS
ACLED
anomaly-detection
Using rolling-average deviation and permutation testing to find where political violence and trade disruption coincide — and asking whether that overlap is more than chance.
NoteA note on how this was made
This post is an exercise in what I’ve been calling vibe coding — analytical work done entirely through natural language, on my phone, using Claude Dispatch. No IDE, no terminal, no keyboard. I described what I wanted to explore, Claude wrote the code and ran it, I reviewed the charts and pushed back when something looked wrong, and we iterated. The only thing I did manually was download the source data files.
The code you see below is the direct output of that process. I’ve cleaned up the narrative, but the analysis is exactly what emerged from that back-and-forth.
Motivation
When a country’s trade volumes shift suddenly, something happened. Maybe it’s a pandemic, a sanctions regime taking hold, a civil war disrupting supply chains, or a regime change reshuffling trading relationships. Trade data is publicly available, high-frequency, and covers nearly every country in the world — which makes it an interesting early-warning signal if you can separate noise from meaningful disruption.
The IMF’s International Merchandise Trade Statistics (IMTS) dataset gives us monthly goods exports and imports for 227 reporting countries, all the way back to 2017. The ACLED dataset gives us monthly counts of political violence events for 245 countries over the same period.
The question this post explores: can we detect anomalous months in trade data, apply the same detection to violence data, and test whether those anomalies co-occur more often than chance?
The short answer is: sometimes yes, but less often than you might hope, and mostly for the countries where you’d expect it.
The Data
IMF IMTS
The IMF makes its IMTS data available via an SDMX 3.0 API, but for this analysis I downloaded the full bulk flat file — 402,443 rows covering 227 reporting countries, 108 monthly periods (January 2017 through December 2025), and four trade indicators. Each row is a unique REPORTER.INDICATOR.PARTNER.FREQ combination.
The series code structure encodes everything we need. For instance, UKR.XG_FOB_USD.G001.M is Ukraine’s monthly goods exports (FOB, USD millions) to the world aggregate. G001 is the IMF’s code for the world total — filtering on this partner gives us each country’s total trade volume rather than any bilateral relationship.
Show code
from IPython.display import Markdown, display
_n_reporters = imts["reporter"].nunique()
_span_start = _monthly_cols[0][:4] + "-" + _monthly_cols[0][6:]
_span_end = _monthly_cols[-1][:4] + "-" + _monthly_cols[-1][6:]
_n_months = len(_monthly_cols)
_indicators = sorted(imts["indicator"].unique())
display(Markdown(f"""
| | |
|---|---|
| **Reporting countries** | {_n_reporters} |
| **Time span** | {_span_start} → {_span_end} ({_n_months} months) |
| **Indicators** | {", ".join(_indicators)} |
| **Unit** | USD millions (exports FOB, imports CIF) |
| **Source** | IMF International Merchandise Trade Statistics (IMTS 1.0.0) |
"""))| Reporting countries | 227 |
| Time span | 2017-01 → 2025-12 (108 months) |
| Indicators | MG_CIF_USD, MG_FOB_USD, TBG_USD, XG_FOB_USD |
| Unit | USD millions (exports FOB, imports CIF) |
| Source | IMF International Merchandise Trade Statistics (IMTS 1.0.0) |
ACLED Violence Data
The Armed Conflict Location & Event Data Project (ACLED) tracks political violence events globally. Their monthly country-level counts give us a measure of conflict intensity that we can align with the trade data. It covers 245 countries with data starting in 1997, though with much better coverage from 2017 onward — conveniently aligned with the IMTS window.
First Look: Global Trade Volume
Before looking at individual countries, it helps to see the aggregate. Summing all reporting countries’ exports to the world gives a useful baseline — the broad strokes of global trade over the period.
Show code
_world_exp = imts[
(imts["indicator"] == "XG_FOB_USD") & (imts["partner"] == "G001")
]
_global_ts = _world_exp[_monthly_cols].sum() / 1_000
fig, ax = plt.subplots(figsize=(11, 4))
ax.fill_between(_dates, _global_ts.values, alpha=0.18, color="steelblue")
ax.plot(_dates, _global_ts.values, color="steelblue", lw=1.8)
ax.axvspan(pd.Timestamp("2020-03-01"), pd.Timestamp("2020-08-01"),
alpha=0.12, color="gray", label="COVID shock")
ax.axvspan(pd.Timestamp("2021-10-01"), pd.Timestamp("2023-01-01"),
alpha=0.08, color="peru", label="Commodity surge")
ax.yaxis.set_major_formatter(mtick.FuncFormatter(lambda x, _: f"${x:,.0f}B"))
ax.set_ylabel("USD billions / month")
ax.legend(frameon=False, fontsize=9)
ax.set_title("Global Merchandise Exports — All Reporting Countries (IMTS)")
plt.tight_layout()
plt.show()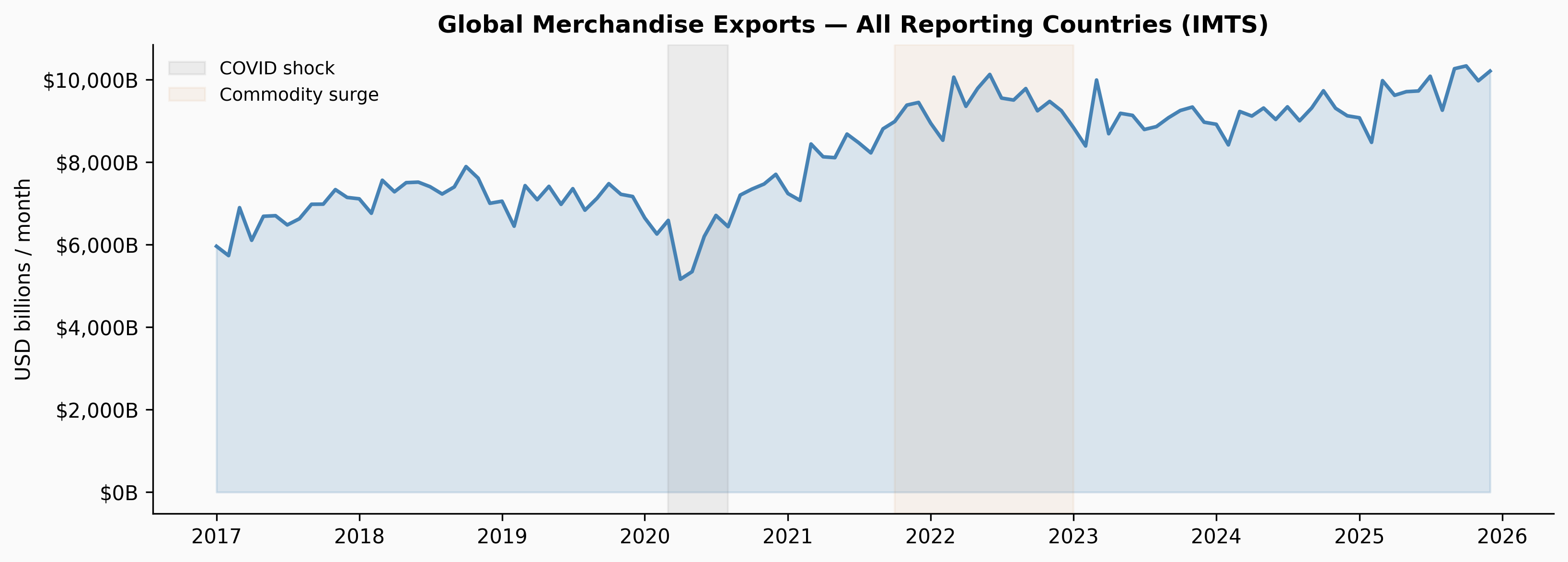
The COVID shock in early 2020 is the clearest feature — a sharp cliff followed by a rapid recovery. The commodity surge from late 2021 through 2022 (driven by energy prices post-Ukraine invasion and supply chain disruptions) pushed aggregate trade values to all-time highs before normalising through 2023–2024.
Country Deep-Dives
With the global picture established, we look at six countries selected for their varied relationships with political violence and economic disruption: Ukraine, Denmark, Venezuela, Yemen, Kenya, and Mexico.
For each country, four panels tell the story: gross trade flows, trade balance, political violence events, and the share of trade with each country’s top 10 bilateral partners over time.
Show code
_MN_TO_BN = 1_000.0
_PALETTE = [
"#4c78a8", "#f58518", "#e45756", "#72b7b2",
"#54a24b", "#b279a2", "#ff9da7", "#9d755d", "#bab0ac", "#eeca3b",
]
TARGETS = {
"UKR": "Ukraine",
"DNK": "Denmark",
"VEN": "Venezuela",
"YEM": "Yemen",
"KEN": "Kenya",
"MEX": "Mexico",
}
def _get_trade_ts(code):
exp = imts[(imts["reporter"] == code) & (imts["indicator"] == "XG_FOB_USD") & (imts["partner"] == "G001")]
imp = imts[(imts["reporter"] == code) & (imts["indicator"] == "MG_CIF_USD") & (imts["partner"] == "G001")]
e = exp[_monthly_cols].sum() / _MN_TO_BN if len(exp) else pd.Series(np.nan, index=_monthly_cols)
i = imp[_monthly_cols].sum() / _MN_TO_BN if len(imp) else pd.Series(np.nan, index=_monthly_cols)
df = pd.DataFrame({"exports": e.values, "imports": i.values}, index=_dates)
df["balance"] = df["exports"] - df["imports"]
return df
def _get_partner_shares(code, top_n=10):
sub = imts[
(imts["reporter"] == code) &
(imts["indicator"].isin(["XG_FOB_USD", "MG_CIF_USD"])) &
(imts["partner"].str.match(r"^[A-Z]{3}$"))
].copy()
if sub.empty: return pd.DataFrame()
sub["_all"] = sub[_monthly_cols].sum(axis=1)
top = sub.groupby("partner")["_all"].sum().nlargest(top_n).index.tolist()
ts = sub[sub["partner"].isin(top)].groupby("partner")[_monthly_cols].sum().T
ts.index = _dates
ts = ts.replace(0, np.nan).dropna(how="all")
row_sums = ts.sum(axis=1).replace(0, np.nan)
pct = (ts.div(row_sums, axis=0) * 100).fillna(0)
return pct[pct.mean().sort_values(ascending=False).index]
def _get_violence_ts(name):
sub = violence[violence["country"] == name].copy()
return sub.set_index("date")["events"].sort_index()
def _plot_country(code, name):
trade = _get_trade_ts(code)
shares = _get_partner_shares(code)
viol = _get_violence_ts(name)
fig, axes = plt.subplots(2, 2, figsize=(13, 8))
fig.suptitle(f"{name} ({code})", fontsize=14, fontweight="bold")
ax0, ax1, ax2, ax3 = axes.flatten()
ax0.plot(trade.index, trade["exports"], color="steelblue", lw=1.6, label="Exports (FOB)")
ax0.plot(trade.index, trade["imports"], color="firebrick", lw=1.6, alpha=0.85, label="Imports (CIF)")
ax0.yaxis.set_major_formatter(mtick.FuncFormatter(lambda x, _: f"${x:.1f}B"))
ax0.legend(frameon=False, fontsize=8)
ax0.set_title("Gross Trade vs. World")
ax0.set_ylabel("USD bn / month")
bal = trade["balance"]
ax1.fill_between(trade.index, bal, 0, where=bal < 0, color="firebrick", alpha=0.3)
ax1.fill_between(trade.index, bal, 0, where=bal >= 0, color="steelblue", alpha=0.3)
ax1.plot(trade.index, bal, color="black", lw=1.1)
ax1.axhline(0, color="black", lw=0.7)
ax1.yaxis.set_major_formatter(mtick.FuncFormatter(lambda x, _: f"${x:.1f}B"))
ax1.set_title("Trade Balance")
ax1.set_ylabel("USD bn / month")
if not viol.empty:
ax2.bar(viol.index, viol.values, width=25, color="#e45756", alpha=0.7)
ax2.yaxis.set_major_formatter(mtick.FuncFormatter(lambda x, _: f"{x:,.0f}"))
else:
ax2.text(0.5, 0.5, "No conflict data available", ha="center", va="center",
transform=ax2.transAxes, color="gray")
ax2.set_title("Political Violence Events (ACLED)")
ax2.set_ylabel("Events / month")
if not shares.empty:
bottom = np.zeros(len(shares))
for j, col in enumerate(shares.columns):
vals = shares[col].values
ax3.fill_between(shares.index, bottom, bottom + vals,
color=_PALETTE[j % len(_PALETTE)], alpha=0.82, label=col)
bottom += vals
ax3.set_ylim(0, 108)
ax3.yaxis.set_major_formatter(mtick.FuncFormatter(lambda x, _: f"{x:.0f}%"))
ax3.legend(frameon=False, fontsize=7, loc="upper left", ncol=2,
title="Partner (ISO-3)", title_fontsize=7)
else:
ax3.text(0.5, 0.5, "No bilateral data available", ha="center", va="center",
transform=ax3.transAxes, color="gray")
ax3.set_title("Top-10 Partner Trade Share")
ax3.set_ylabel("% of bilateral total")
plt.tight_layout()
plt.show()Show code
for code, name in TARGETS.items():
_plot_country(code, name)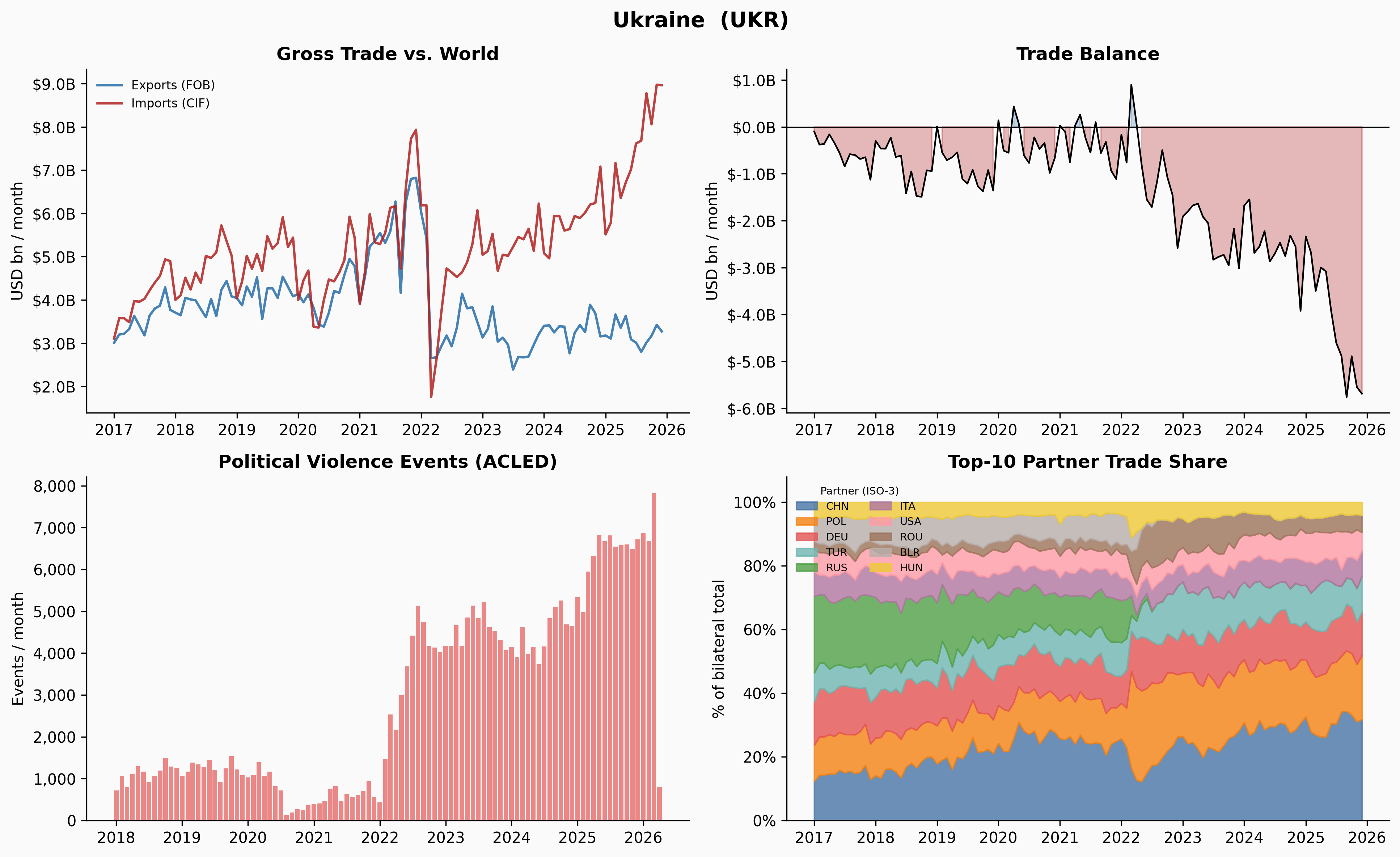
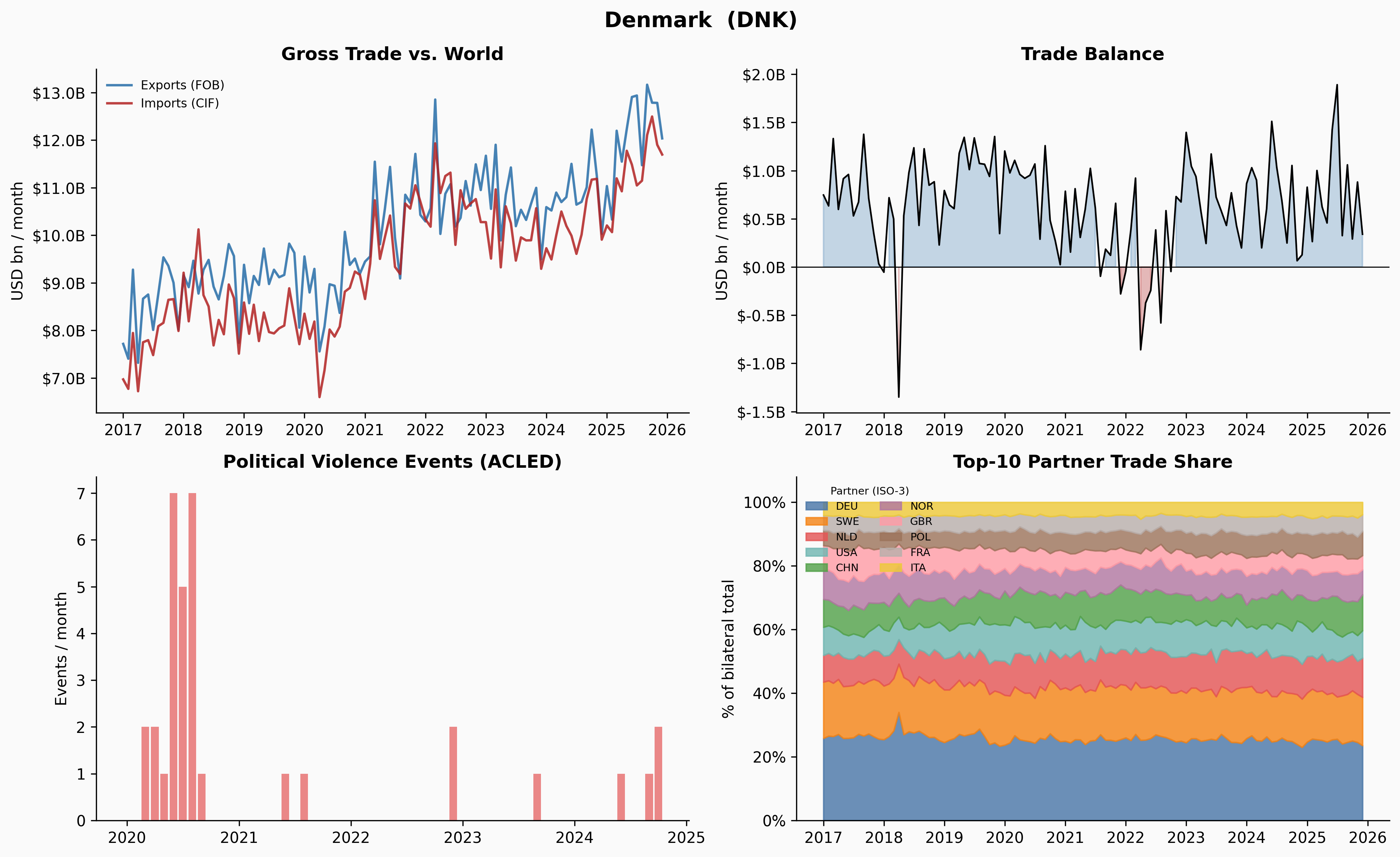
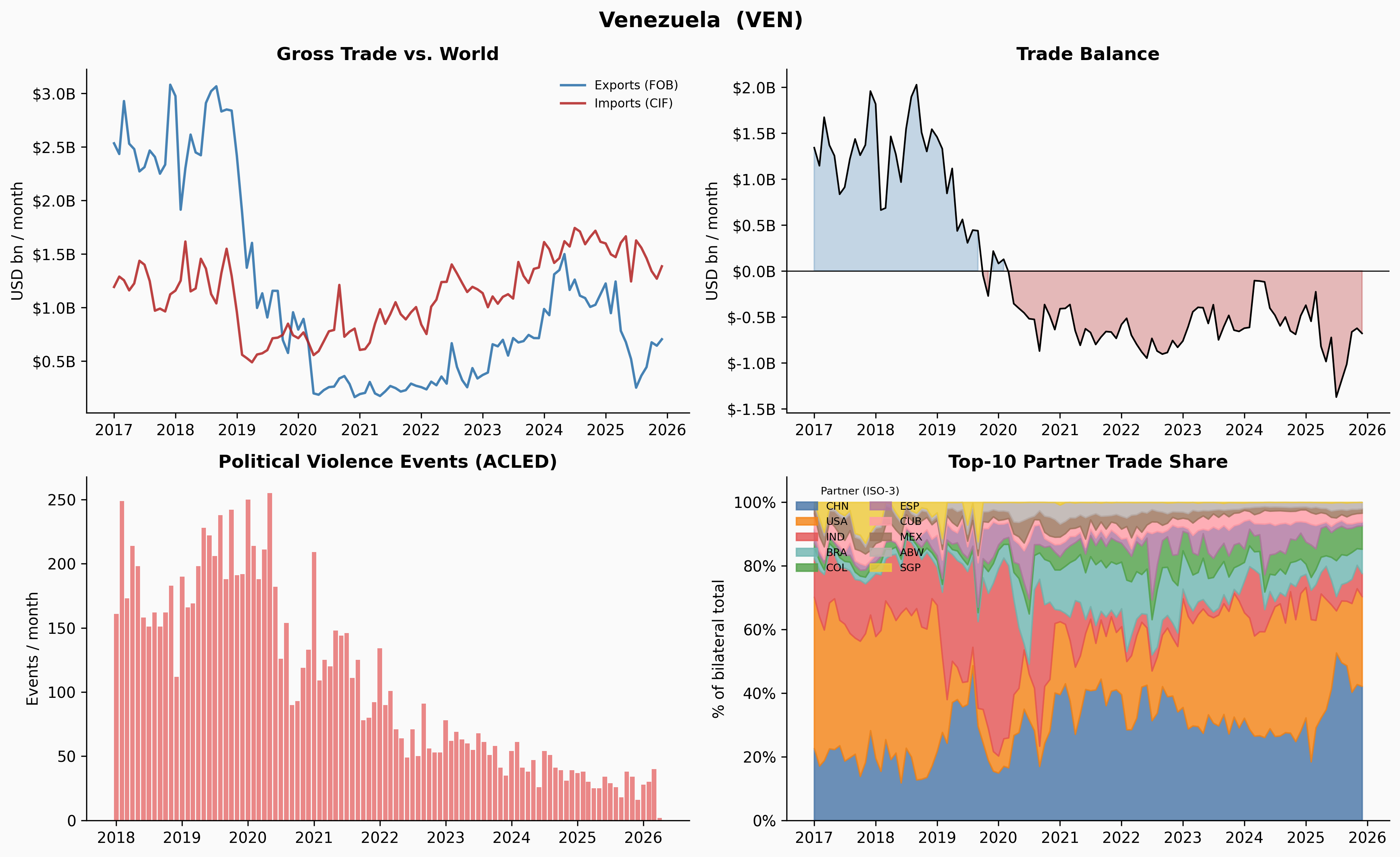
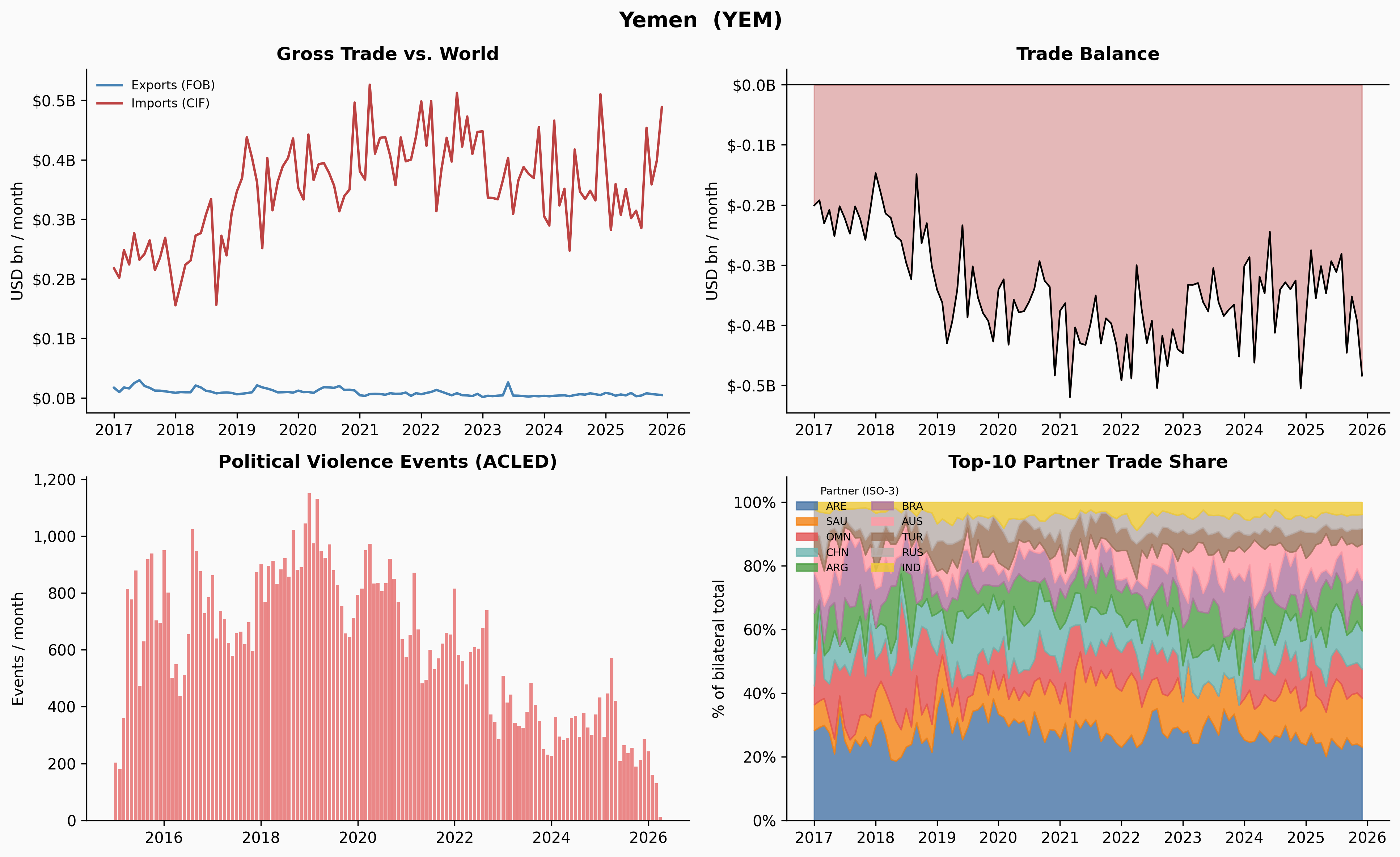
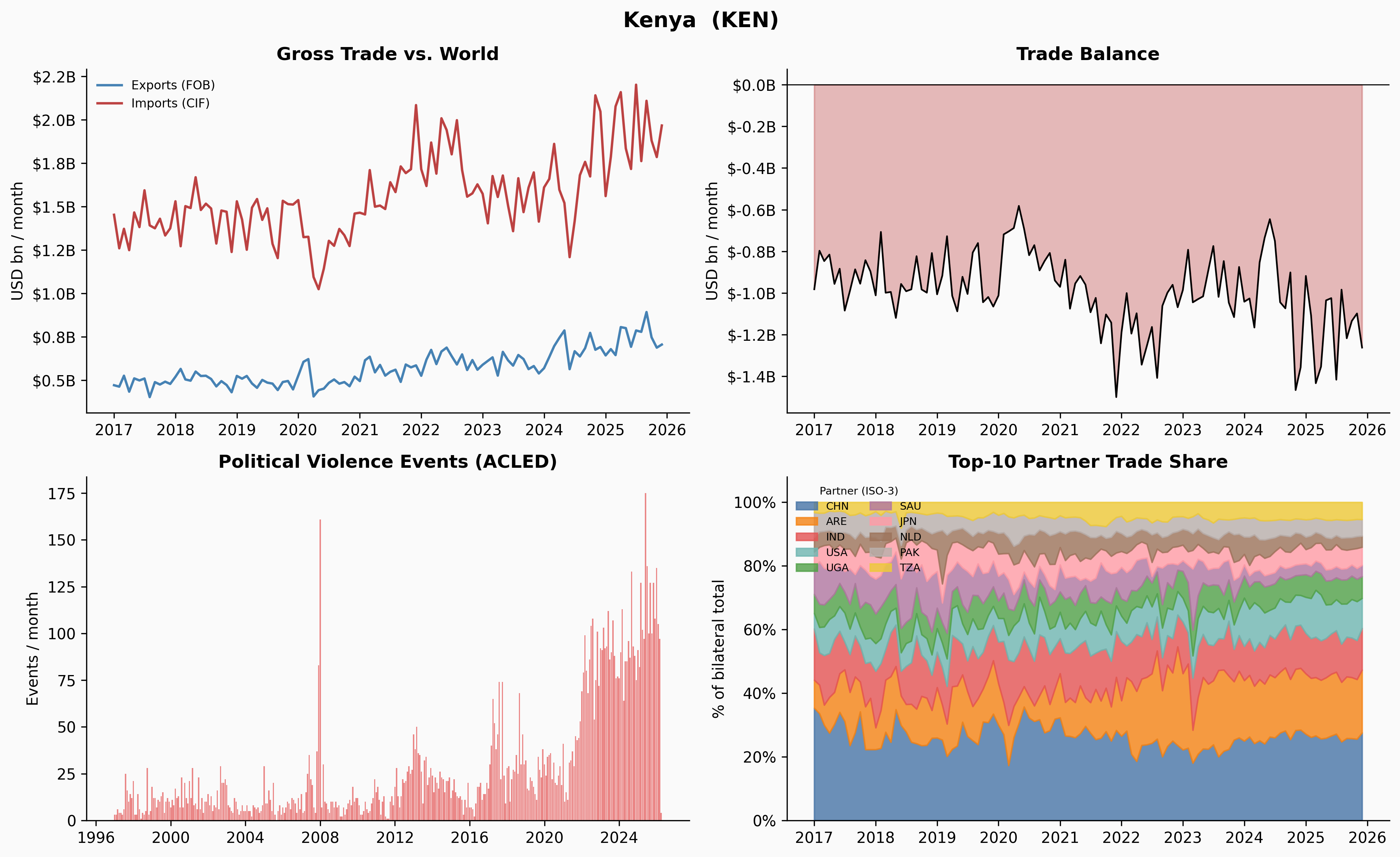
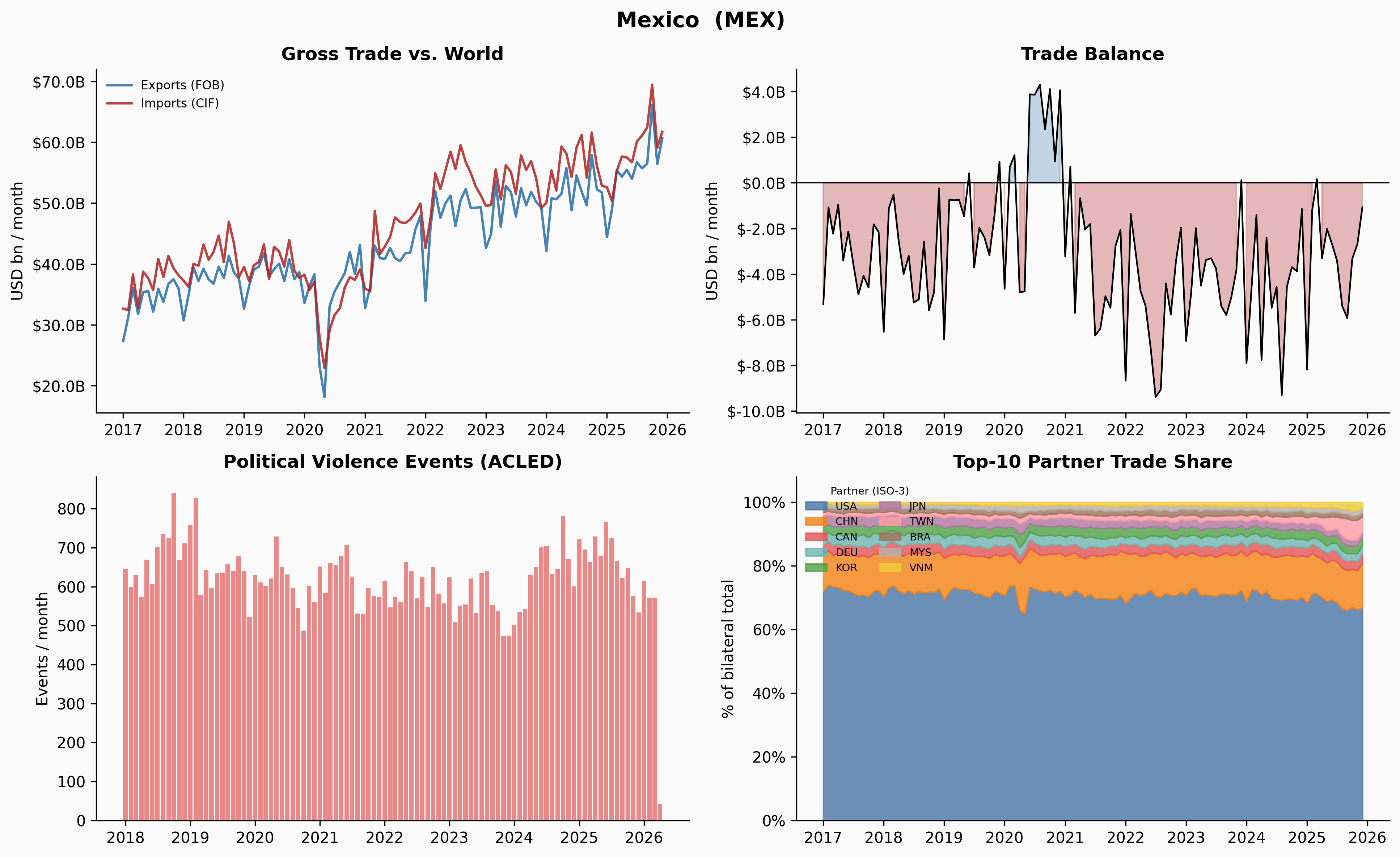
A few things jump out immediately. Ukraine’s trade collapses sharply in early 2022 — and the Russia share in Panel 4 drops to near-zero at exactly the same moment. Venezuela’s trade contracted steadily from 2018 through 2020, losing about 65% of its volume before stabilising. Yemen’s trade is characteristically volatile throughout, driven by the ongoing blockade and conflict. Denmark, by contrast, is almost disappointingly quiet.
Anomaly Detection
The Problem with Simple Month-over-Month Thresholds
The most obvious approach to flagging unusual months is to look at month-over-month percentage changes and flag anything in the tails. But this has a structural flaw: by definition, there will always be outliers. If you define anomalies as the top and bottom 5% of a single country’s MoM distribution, you’ll always find them — even if the country’s trade is perfectly stable.
This gave us three angles to try, with increasing sophistication:
Cross-country distribution: pool MoM changes across all 227 countries and flag anything in the global tails. This ensures the threshold is calibrated to what counts as extreme by world standards — a country would have to move more than 97% of all country-months to get flagged. The downside: volatile countries (Yemen, Venezuela) might dominate the tails regardless of whether anything unusual happened.
Within-country z-score: flag months where the MoM change is more than 2σ from that country’s own historical mean. This asks “is this unusual for this country?” but inherits the same problem — you’re guaranteed to find something if you wait long enough.
Rolling 12-month average deviation: compute a trailing 12-month average of trade volume, measure how far each month sits from that average, then flag the tails of that distribution. This turned out to be the most useful method, and it’s worth understanding why.
The Rolling Average Method
Show code
def rolling_flags(series, window=12, z_thresh=2.0):
"""
Flag months where trade volume deviates from its 12-month rolling
average by more than z_thresh standard deviations.
The rolling mean acts as a local baseline — it follows the trend,
so gradual shifts show up as growing gaps rather than small steps.
"""
roll_mean = series.rolling(window, min_periods=6).mean()
dev = (series - roll_mean) / roll_mean.replace(0, np.nan)
dev = dev.replace([np.inf, -np.inf], np.nan).dropna()
if len(dev) < 10 or dev.std() == 0:
return pd.Series(dtype=bool), dev, roll_mean
z = (dev - dev.mean()) / dev.std()
return z.abs() > z_thresh, dev, roll_meanThe key insight is that the rolling average lags. When Venezuela’s trade fell from $4.1B/month in late 2018 to $1.4B by late 2019 — a 65% collapse — no single month-over-month change was large enough to trigger a simple threshold. The biggest individual drops were around 27%, just inside a ±28% within-country threshold. But by mid-2019, the rolling average still reflected the healthier levels from 6–12 months prior, so the deviation between current trade and the rolling baseline had grown large enough to flag.
Show code
_COLORS = {
"cross": "#e45756",
"within": "#4c78a8",
"roll": "#54a24b",
"none": "#d0d0d0",
}
def method_color(fc, fw, fr):
n = sum([fc, fw, fr])
if n == 0: return _COLORS["none"]
if n == 3: return "#b279a2"
if fc and fw: return "#f58518"
if fc and fr: return "#e4a0a0"
if fw and fr: return "#72b7b2"
if fc: return _COLORS["cross"]
if fw: return _COLORS["within"]
return _COLORS["roll"]
# Cross-country distribution thresholds
_trade_world = imts[
(imts["indicator"].isin(["XG_FOB_USD", "MG_CIF_USD"])) &
(imts["partner"] == "G001")
].groupby("reporter")[_monthly_cols].sum()
_trade_world.columns = _dates
_mom_all = _trade_world.pct_change(axis=1).replace([np.inf, -np.inf], np.nan)
_flat = _mom_all.values.flatten()
_flat = _flat[np.isfinite(_flat)]
CC_LO = np.percentile(_flat, 3)
CC_HI = np.percentile(_flat, 97)
WC_Z = 2.0
for code, name in TARGETS.items():
if code not in _mom_all.index: continue
trade_s = _trade_world.loc[code].sort_index() / 1000
flag_roll, roll_dev, roll_mean = rolling_flags(trade_s)
mom = _mom_all.loc[code].dropna()
wc_z = (mom - mom.mean()) / mom.std() if mom.std() > 0 else mom * 0
flag_cross = (mom < CC_LO) | (mom > CC_HI)
flag_within = wc_z.abs() > WC_Z
common = mom.index.intersection(roll_dev.index)
fc = flag_cross.reindex(common, fill_value=False)
fw = flag_within.reindex(common, fill_value=False)
fr = flag_roll.reindex(common, fill_value=False)
fig, axes = plt.subplots(2, 2, figsize=(14, 8))
fig.suptitle(f"{name} — Three-Method Anomaly Detection", fontsize=13, fontweight="bold")
ax0, ax1, ax2, ax3 = axes.flatten()
# Panel 1: Trade + rolling avg + markers
ax0.fill_between(trade_s.index, trade_s.values, alpha=0.12, color="steelblue")
ax0.plot(trade_s.index, trade_s.values, color="steelblue", lw=1.5, label="Monthly trade")
ax0.plot(roll_mean.index, roll_mean.values, color="black", lw=1.1, ls="--", alpha=0.55, label="12-mo avg")
for idx in common:
c = method_color(fc[idx], fw[idx], fr[idx])
if c != _COLORS["none"]:
ax0.axvline(idx, color=c, alpha=0.4, lw=1.8)
ax0.yaxis.set_major_formatter(mtick.FuncFormatter(lambda x, _: f"${x:.1f}B"))
ax0.legend(frameon=False, fontsize=8)
ax0.set_title("Trade + 12-Month Rolling Avg")
ax0.set_ylabel("USD bn / month")
# Panel 2: Rolling deviation bars
rd_mean, rd_std = roll_dev.mean(), roll_dev.std()
ax1.bar(roll_dev.index, roll_dev.values * 100,
color=[_COLORS["roll"] if flag_roll.get(i, False) else
("#aed6a8" if roll_dev[i] >= 0 else "#f7b6b5") for i in roll_dev.index],
width=25, linewidth=0)
ax1.axhline(0, color="black", lw=0.7)
ax1.axhline((rd_mean + WC_Z * rd_std) * 100, color=_COLORS["roll"], ls="--", lw=1.2, alpha=0.8,
label=f"±{WC_Z}σ")
ax1.axhline((rd_mean - WC_Z * rd_std) * 100, color=_COLORS["roll"], ls="--", lw=1.2, alpha=0.8)
ax1.yaxis.set_major_formatter(mtick.FuncFormatter(lambda x, _: f"{x:.0f}%"))
ax1.legend(frameon=False, fontsize=8)
ax1.set_title("% Deviation from Rolling Avg")
ax1.set_ylabel("% deviation")
# Panel 3: Cross-country score
cc_iqr = np.percentile(_flat, 75) - np.percentile(_flat, 25)
cc_med = np.percentile(_flat, 50)
cc_z = (mom - cc_med) / cc_iqr
cc_thresh = (CC_HI - cc_med) / cc_iqr
ax2.fill_between(mom.index, cc_z.values, 0,
where=flag_cross.reindex(mom.index, fill_value=False).values,
color=_COLORS["cross"], alpha=0.5, label="Flagged")
ax2.plot(mom.index, cc_z.values, color=_COLORS["cross"], lw=1.3)
ax2.axhline(cc_thresh, color=_COLORS["cross"], ls="--", lw=1.1, alpha=0.7)
ax2.axhline(-cc_thresh, color=_COLORS["cross"], ls="--", lw=1.1, alpha=0.7)
ax2.axhline(0, color="black", lw=0.6)
ax2.set_title("Method 1: Cross-Country MoM (global p3/p97)")
ax2.legend(frameon=False, fontsize=8)
# Panel 4: Within-country z-score
ax3.fill_between(wc_z.index, wc_z.values, 0,
where=flag_within.reindex(wc_z.index, fill_value=False).values,
color=_COLORS["within"], alpha=0.5, label="Flagged")
ax3.plot(wc_z.index, wc_z.values, color=_COLORS["within"], lw=1.3)
ax3.axhline(WC_Z, color=_COLORS["within"], ls=":", lw=1.2, alpha=0.8, label=f"±{WC_Z}σ")
ax3.axhline(-WC_Z, color=_COLORS["within"], ls=":", lw=1.2, alpha=0.8)
ax3.axhline(0, color="black", lw=0.6)
ax3.set_title("Method 2: Within-Country MoM (own history)")
ax3.legend(frameon=False, fontsize=8)
patches = [
mpatches.Patch(color=_COLORS["cross"], label=f"Cross-country ({flag_cross.sum()})"),
mpatches.Patch(color=_COLORS["within"], label=f"Within-country ({flag_within.sum()})"),
mpatches.Patch(color=_COLORS["roll"], label=f"Rolling avg ({flag_roll.sum()})"),
]
fig.legend(handles=patches, loc="lower center", ncol=3, frameon=False,
fontsize=9, bbox_to_anchor=(0.5, -0.02))
plt.tight_layout(rect=[0, 0.04, 1, 1])
plt.show()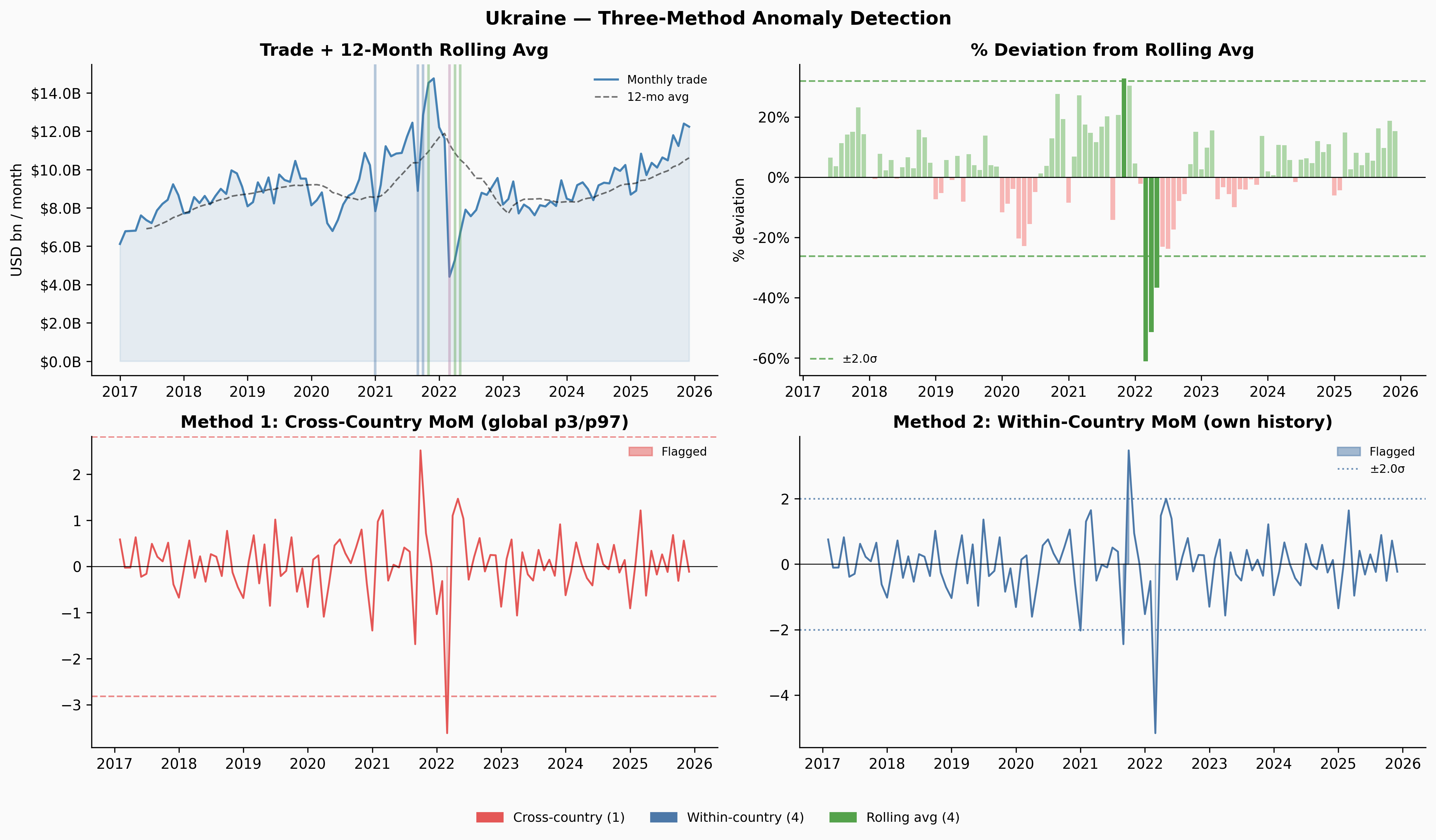
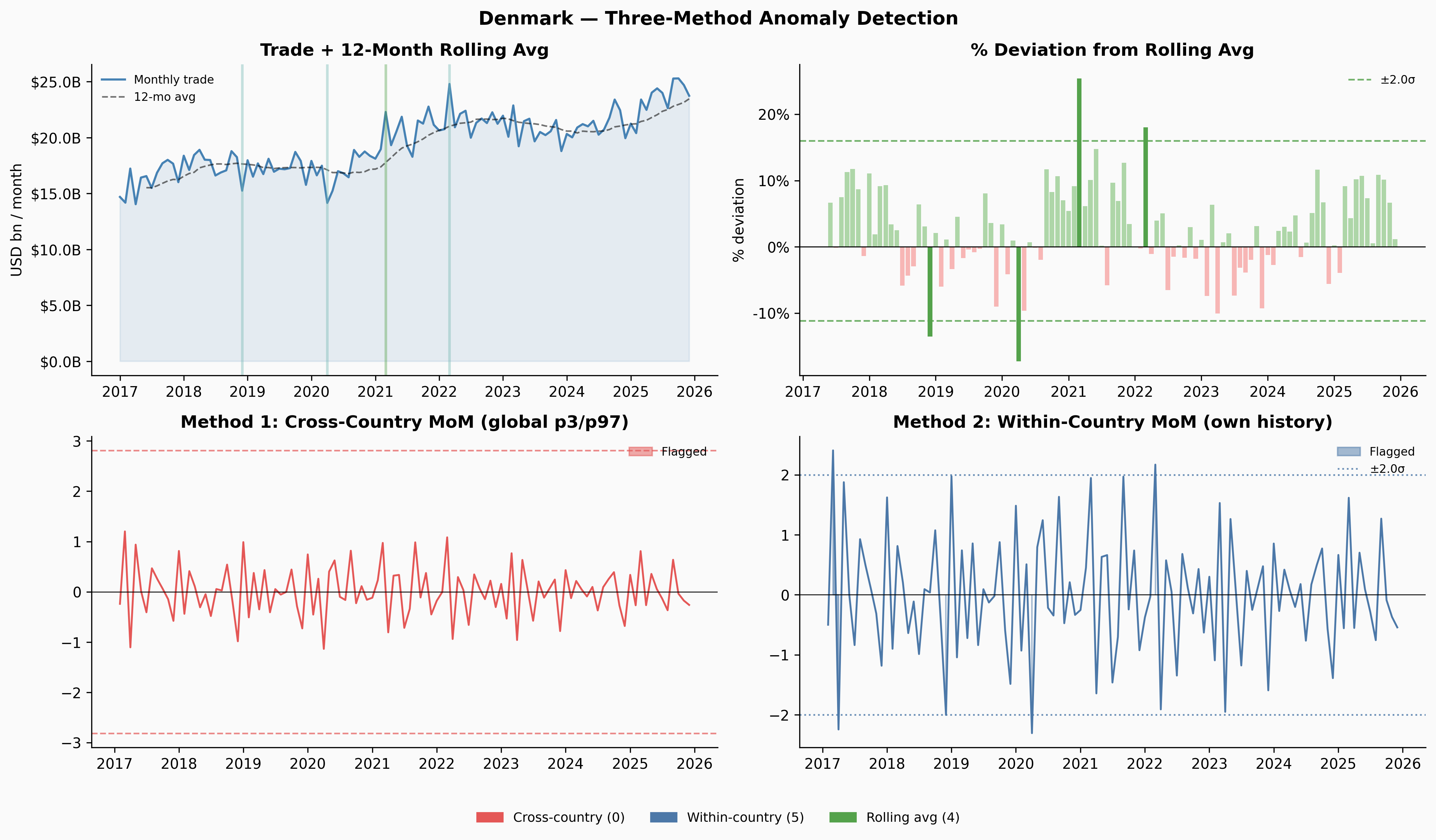
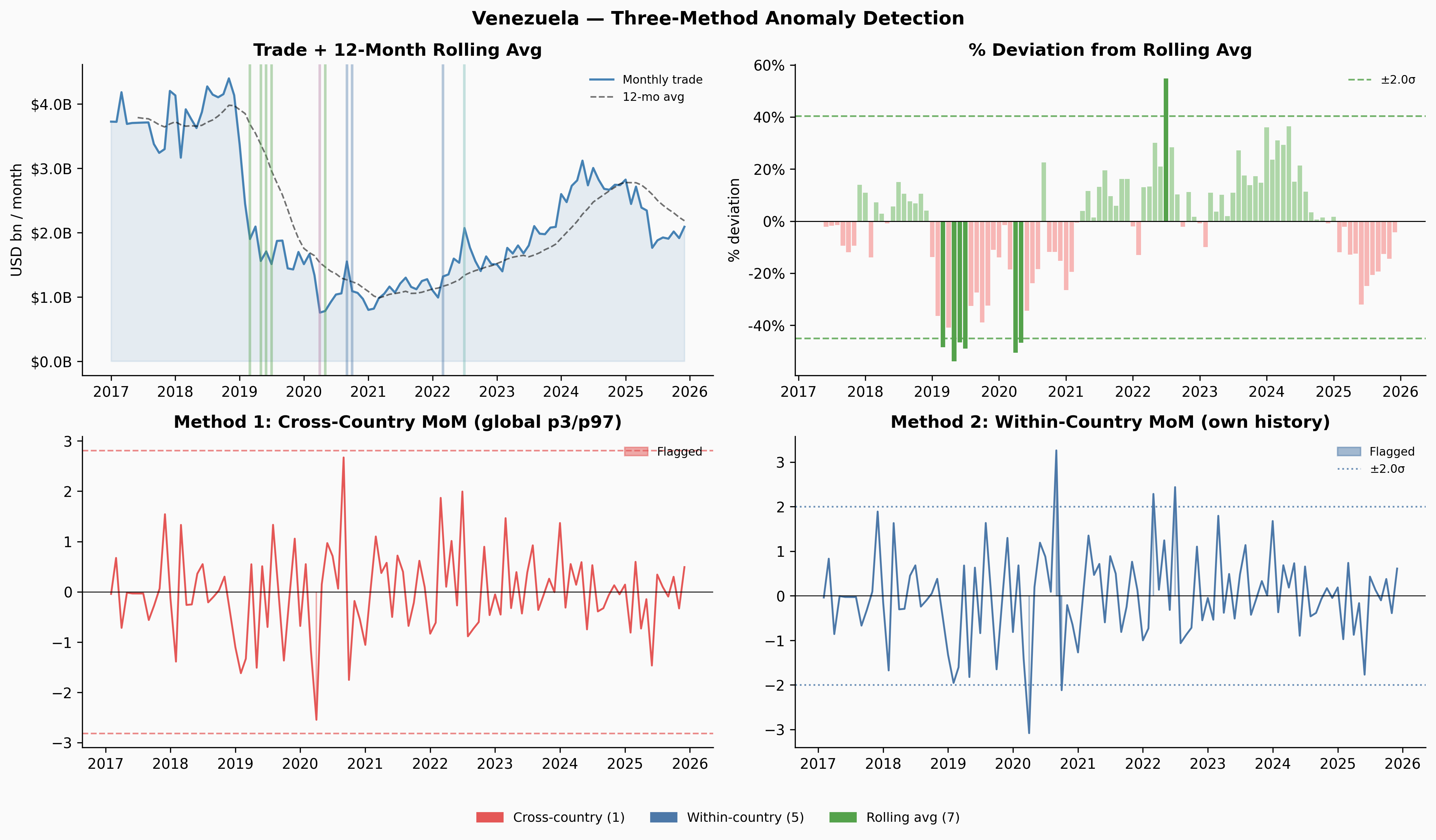
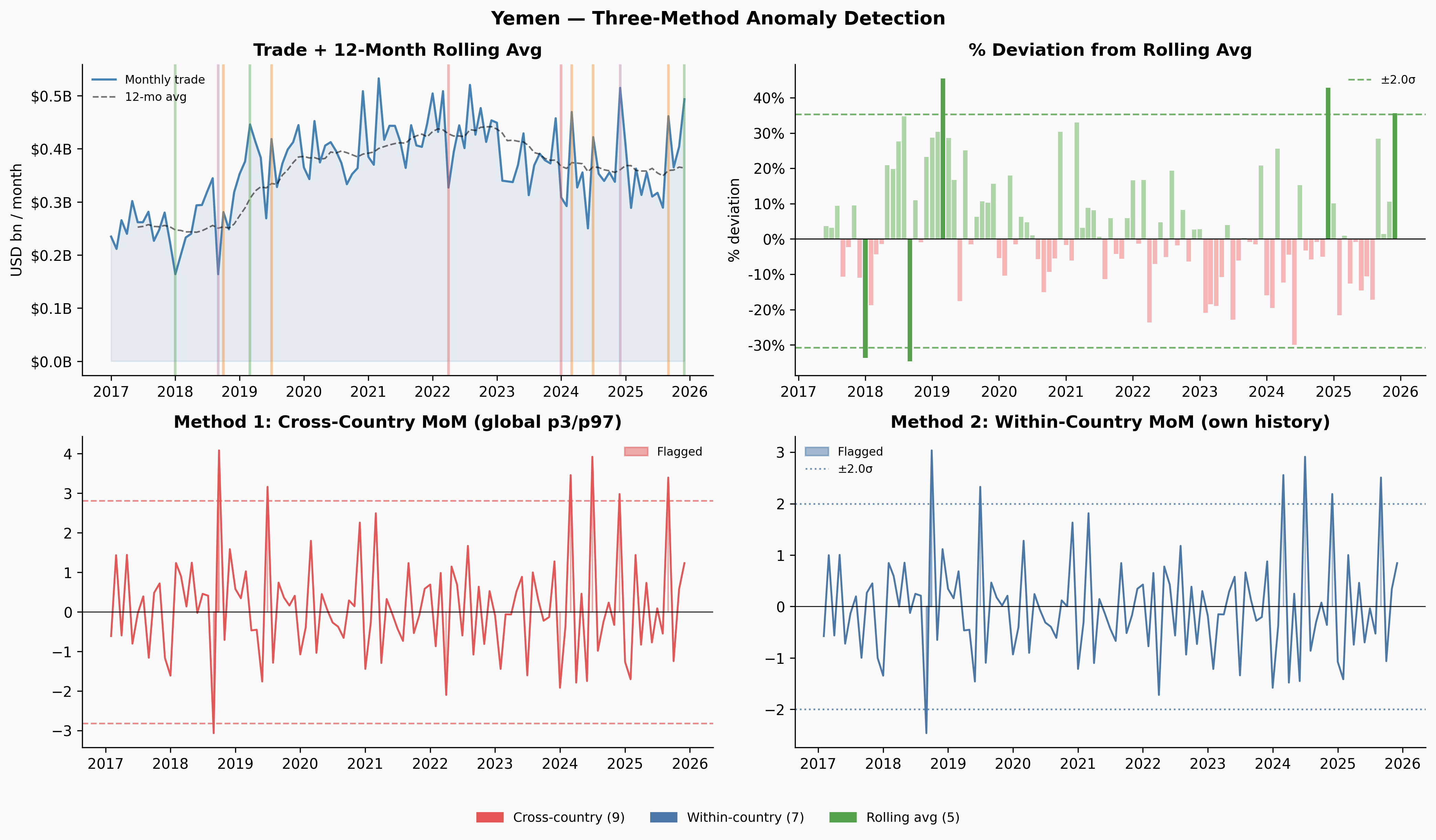
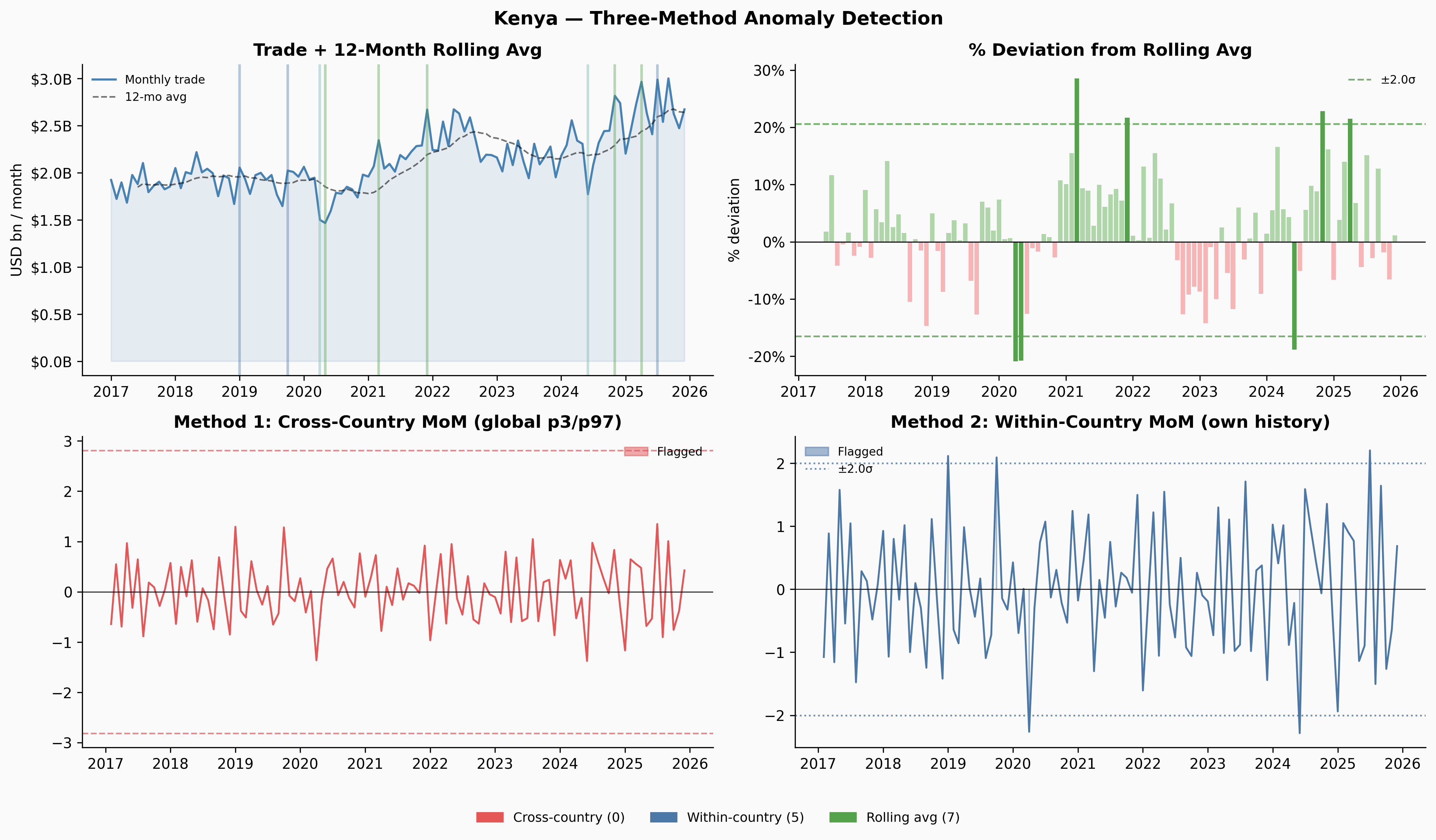
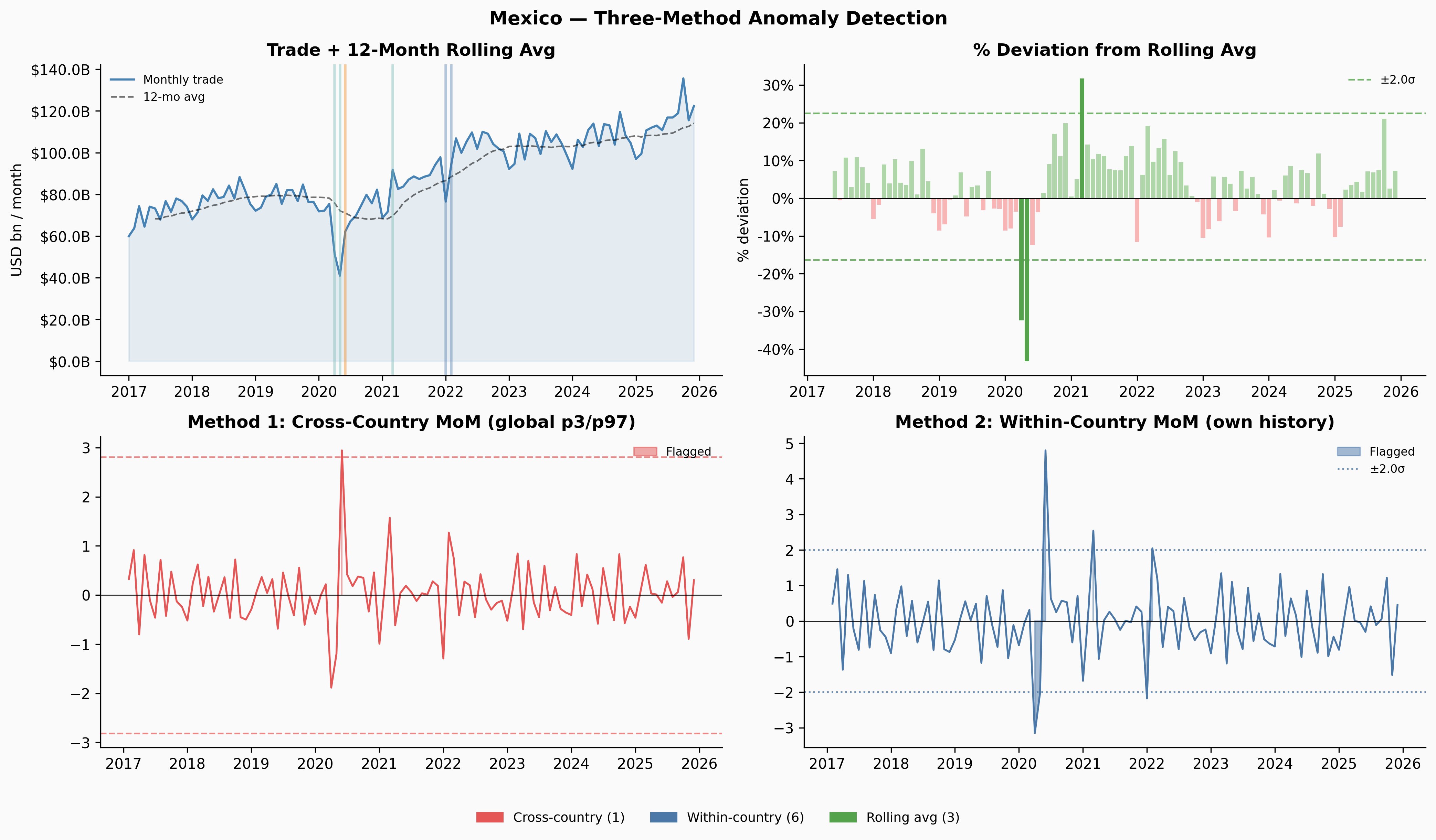
The three methods complement each other. Cross-country only fires when something is genuinely extreme by global standards — Denmark and Kenya never clear that bar at all. Within-country flags more, but those flags are meaningful: they’re saying “this is unusual for this country.” Rolling-average deviation caught Venezuela’s 2019 slow collapse that both MoM methods missed entirely.
Applying the Same Logic to Violence Data
The rolling-average deviation method transfers directly to the ACLED violence data. The same intuition applies: we’re not asking whether a country is violent in absolute terms, but whether its current violence level is unusual relative to its own recent baseline.
Show code
# Build violence time series per country
_viol_by_country = {}
for cname, grp in violence.groupby("country"):
s = grp.set_index("date")["events"].sort_index().resample("MS").sum()
_viol_by_country[cname] = sCo-occurrence: When Trade and Violence Anomalies Align
With both sets of anomaly flags in hand, we can ask a simple question: does a trade anomaly in a given country tend to occur near a violence anomaly?
We define “near” as within a 3-month window. This captures both the possibility that violence causes trade disruption (perhaps with a lag as sanctions are imposed or supply chains reroute) and the possibility that trade disruption precedes or accompanies escalation.
Show code
WINDOW = 3 # months
def windowed_cooccur(flag_trade, flag_viol, window=WINDOW):
"""
Returns the count of months inside any co-occurrence window —
defined as a period where a trade anomaly and a violence anomaly
both occur within `window` months of each other.
"""
trade_m = flag_trade[flag_trade].index
viol_m = flag_viol[flag_viol].index
if len(trade_m) == 0 or len(viol_m) == 0:
return 0
all_idx = flag_trade.index.union(flag_viol.index).sort_values()
co = pd.Series(False, index=all_idx)
for tm in trade_m:
for vm in viol_m:
if abs((tm - vm).days) / 30.44 <= window:
lo, hi = min(tm, vm), max(tm, vm)
co.loc[(co.index >= lo) & (co.index <= hi)] = True
return int(co.sum())Show code
C_TRADE = "#4c78a8"
C_VIOLENCE = "#e45756"
C_BOTH = "#b279a2"
for code, name in TARGETS.items():
trade_s = _trade_world.loc[code].sort_index() / 1000 if code in _trade_world.index else None
if trade_s is None: continue
ft, _, roll_trade = rolling_flags(trade_s)
viol_s = _viol_by_country.get(name)
if viol_s is None: continue
fv, _, roll_viol = rolling_flags(viol_s)
x_lo = max(trade_s.index.min(), viol_s.index.min())
x_hi = min(trade_s.index.max(), viol_s.index.max())
common = ft.index.intersection(fv.index)
ft_c = ft.reindex(common, fill_value=False)
fv_c = fv.reindex(common, fill_value=False)
# Build co-occurrence mask
trade_m = ft_c[ft_c].index; viol_m = fv_c[fv_c].index
all_idx = ft_c.index.union(fv_c.index).sort_values()
co = pd.Series(False, index=all_idx)
for tm in trade_m:
for vm in viol_m:
if abs((tm - vm).days) / 30.44 <= WINDOW:
lo, hi = min(tm, vm), max(tm, vm)
co.loc[(co.index >= lo) & (co.index <= hi)] = True
co_window = co[(co.index >= x_lo) & (co.index <= x_hi)]
fig, axes = plt.subplots(2, 2, figsize=(14, 9))
fig.suptitle(f"{name} — Trade & Violence Anomaly Co-occurrence", fontsize=13, fontweight="bold")
ax0, ax1, ax2, ax3 = axes.flatten()
ax0.fill_between(trade_s.index, trade_s.values, alpha=0.12, color=C_TRADE)
ax0.plot(trade_s.index, trade_s.values, color=C_TRADE, lw=1.5, label="Monthly trade")
ax0.plot(roll_trade.index, roll_trade.values, color="black", lw=1.1, ls="--", alpha=0.55, label="12-mo avg")
for idx in ft_c[ft_c].index:
ax0.axvline(idx, color=C_TRADE, alpha=0.45, lw=1.6)
ax0.yaxis.set_major_formatter(mtick.FuncFormatter(lambda x, _: f"${x:.1f}B"))
ax0.set_xlim(x_lo, x_hi); ax0.legend(frameon=False, fontsize=8)
ax0.set_title(f"Total Trade — rolling-avg anomalies ({ft_c.sum()} months)")
ax0.set_ylabel("USD bn / month")
ax1.bar(viol_s.index, viol_s.values,
color=[C_VIOLENCE if fv.get(d, False) else "#f7b6b5" for d in viol_s.index],
width=25, linewidth=0)
ax1.plot(roll_viol.index, roll_viol.values, color="black", lw=1.1, ls="--", alpha=0.55)
ax1.set_xlim(x_lo, x_hi)
ax1.set_title(f"Violence Events — rolling-avg anomalies ({fv_c.sum()} months)")
ax1.set_ylabel("Events / month")
_, roll_dev_t, _ = rolling_flags(trade_s)
_, roll_dev_v, _ = rolling_flags(viol_s)
ax3b = ax2.twinx()
ax2.plot(roll_dev_t.index, roll_dev_t.values * 100, color=C_TRADE, lw=1.4, label="Trade")
ax3b.plot(roll_dev_v.index, roll_dev_v.values * 100, color=C_VIOLENCE, lw=1.4, alpha=0.8, label="Violence")
ax2.set_xlim(x_lo, x_hi); ax2.axhline(0, color="gray", lw=0.6)
ax2.set_ylabel("Trade % deviation", color=C_TRADE)
ax3b.set_ylabel("Violence % deviation", color=C_VIOLENCE)
ax2.tick_params(axis="y", colors=C_TRADE); ax3b.tick_params(axis="y", colors=C_VIOLENCE)
ax2.set_title("% Deviation from Rolling Avg — both series")
lines1, labs1 = ax2.get_legend_handles_labels()
lines2, labs2 = ax3b.get_legend_handles_labels()
ax2.legend(lines1 + lines2, labs1 + labs2, frameon=False, fontsize=8)
in_window = False; win_start = None
for dt in co_window.index:
if co_window[dt] and not in_window:
win_start = dt; in_window = True
elif not co_window[dt] and in_window:
ax3.axvspan(win_start, dt, alpha=0.2, color=C_BOTH); in_window = False
if in_window: ax3.axvspan(win_start, co_window.index[-1], alpha=0.2, color=C_BOTH)
for idx in ft_c[ft_c].index:
if x_lo <= idx <= x_hi:
ax3.annotate("", xy=(idx, 0.85), xytext=(idx, 0.70),
xycoords=("data","axes fraction"), textcoords=("data","axes fraction"),
arrowprops=dict(arrowstyle="-", color=C_TRADE, lw=2))
for idx in fv_c[fv_c].index:
if x_lo <= idx <= x_hi:
ax3.annotate("", xy=(idx, 0.30), xytext=(idx, 0.15),
xycoords=("data","axes fraction"), textcoords=("data","axes fraction"),
arrowprops=dict(arrowstyle="-", color=C_VIOLENCE, lw=2))
ax3.text(0.02, 0.78, "▌ Trade anomaly", transform=ax3.transAxes, color=C_TRADE, fontsize=8, va="center")
ax3.text(0.02, 0.22, "▌ Violence anomaly", transform=ax3.transAxes, color=C_VIOLENCE, fontsize=8, va="center")
ax3.axhline(0.5, color="gray", lw=0.5, ls="--", alpha=0.4)
ax3.set_xlim(x_lo, x_hi); ax3.set_ylim(0, 1); ax3.set_yticks([])
ax3.set_title(f"Co-occurrence Timeline — purple = within {WINDOW} months")
ax3.spines["left"].set_visible(False)
patches = [
mpatches.Patch(color=C_TRADE, label=f"Trade anomaly ({ft_c.sum()})"),
mpatches.Patch(color=C_VIOLENCE, label=f"Violence anomaly ({fv_c.sum()})"),
mpatches.Patch(color=C_BOTH, label=f"Co-occurrence ({int(co_window.sum())} months)"),
]
fig.legend(handles=patches, loc="lower center", ncol=3, frameon=False,
fontsize=9, bbox_to_anchor=(0.5, -0.01))
plt.tight_layout(rect=[0, 0.04, 1, 1])
plt.show()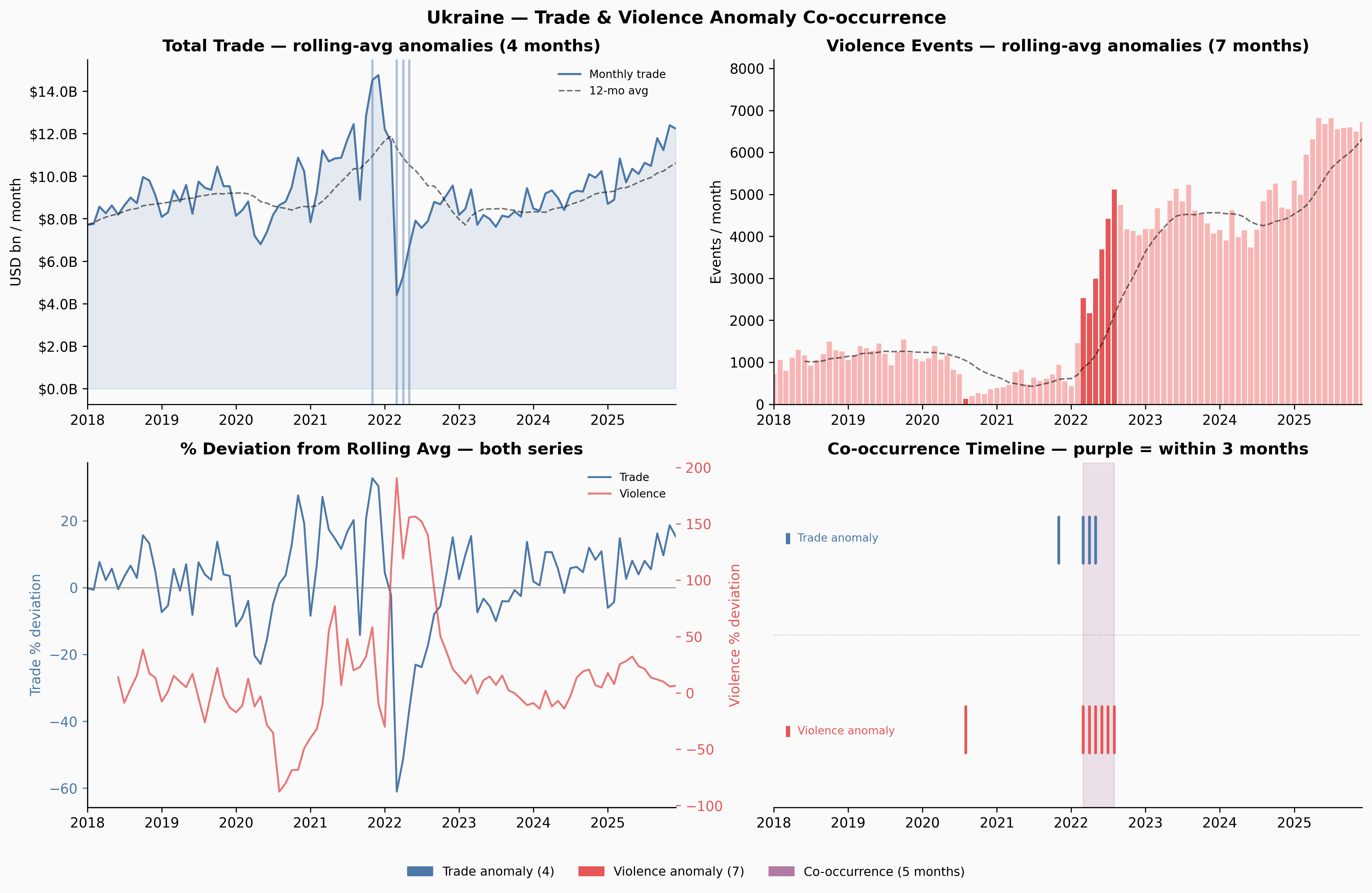
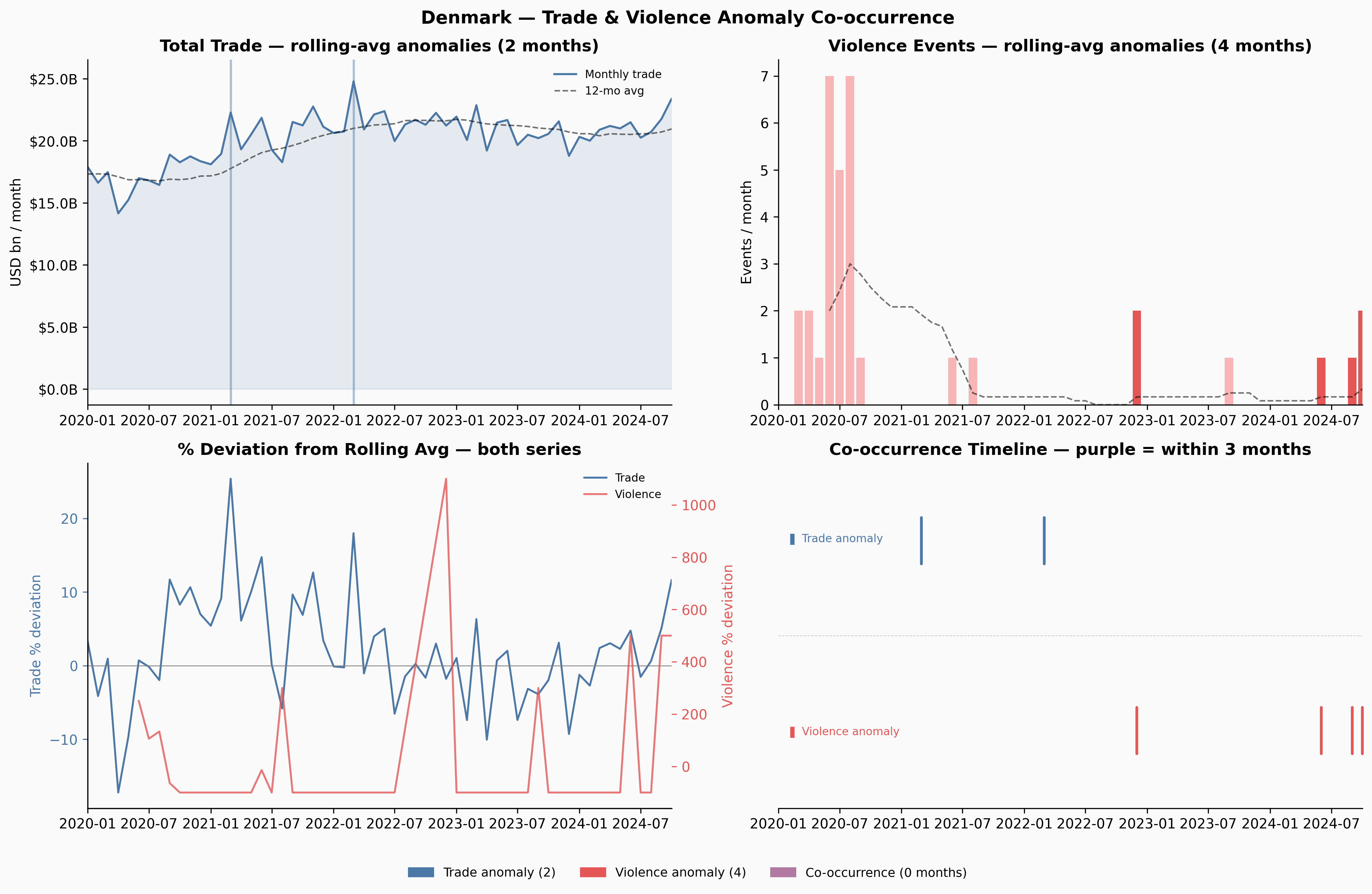
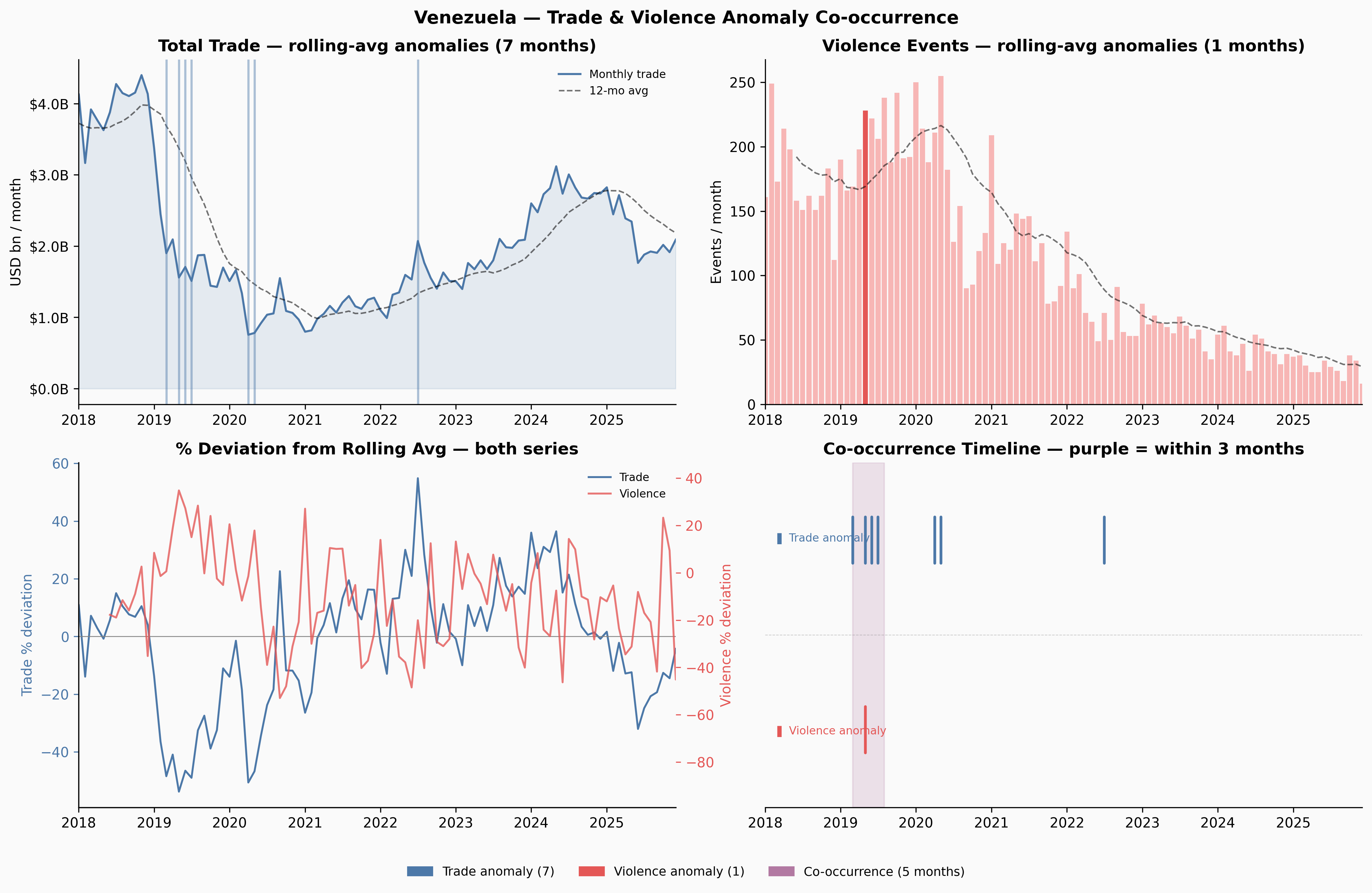
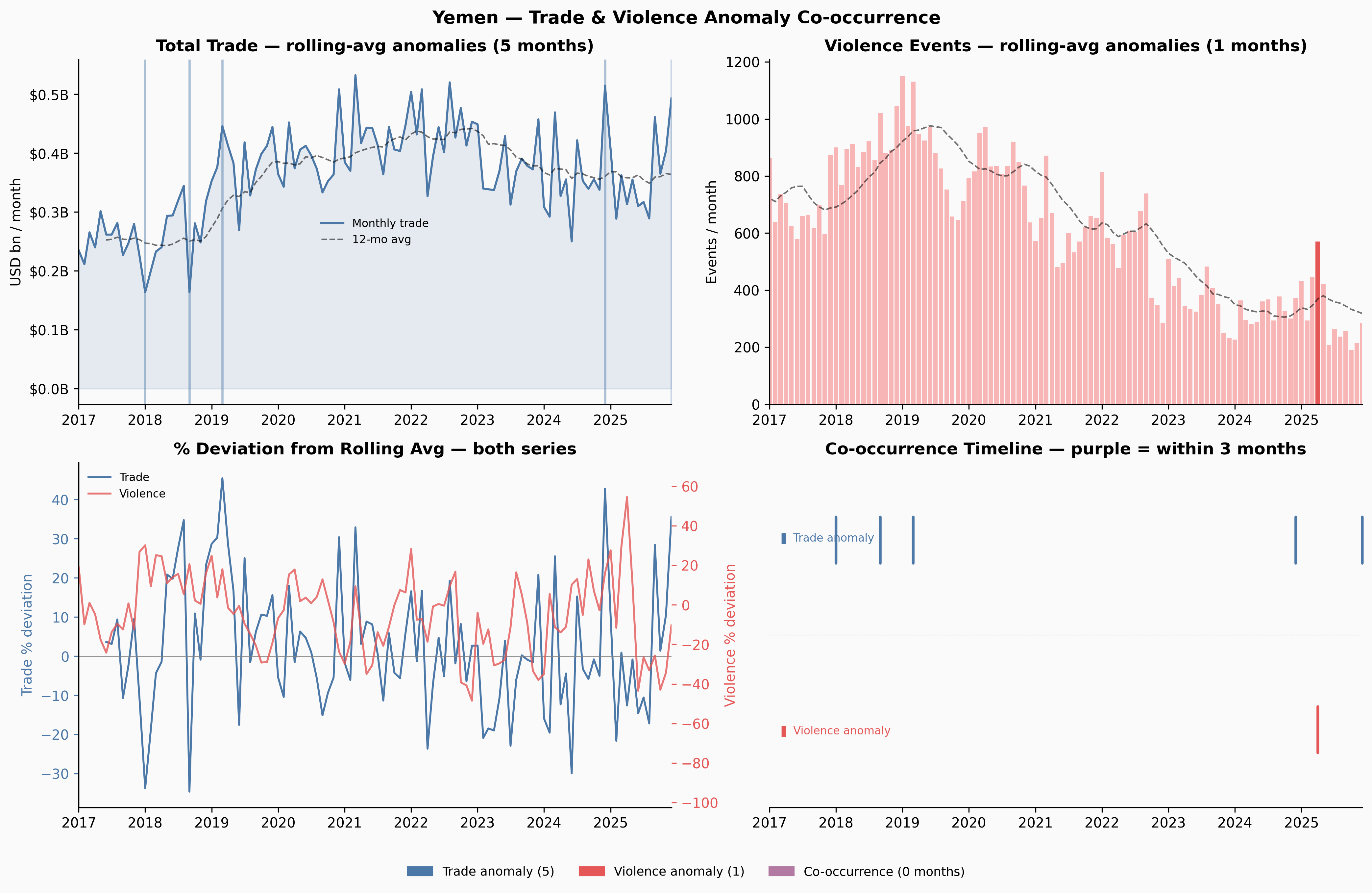
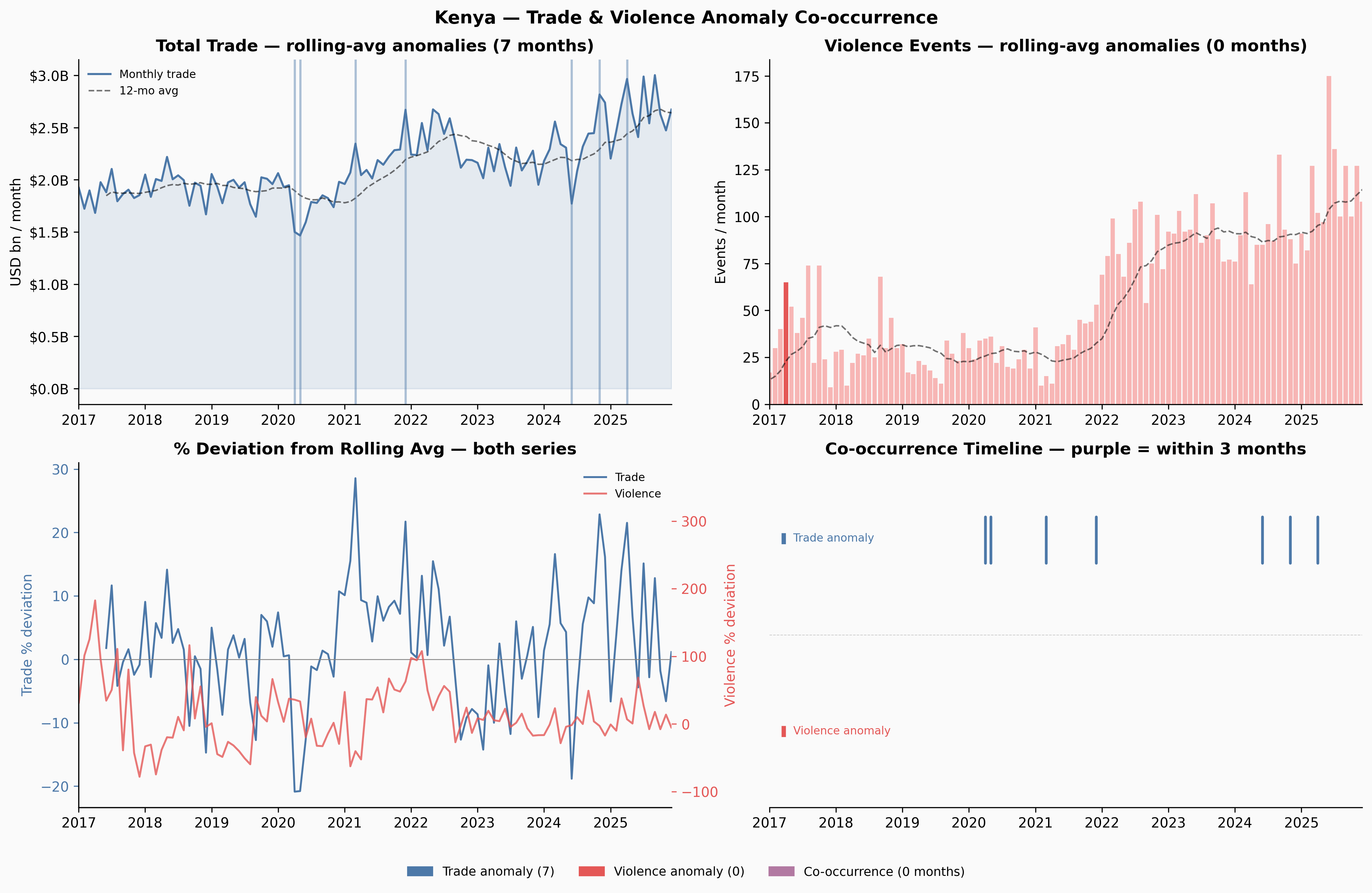
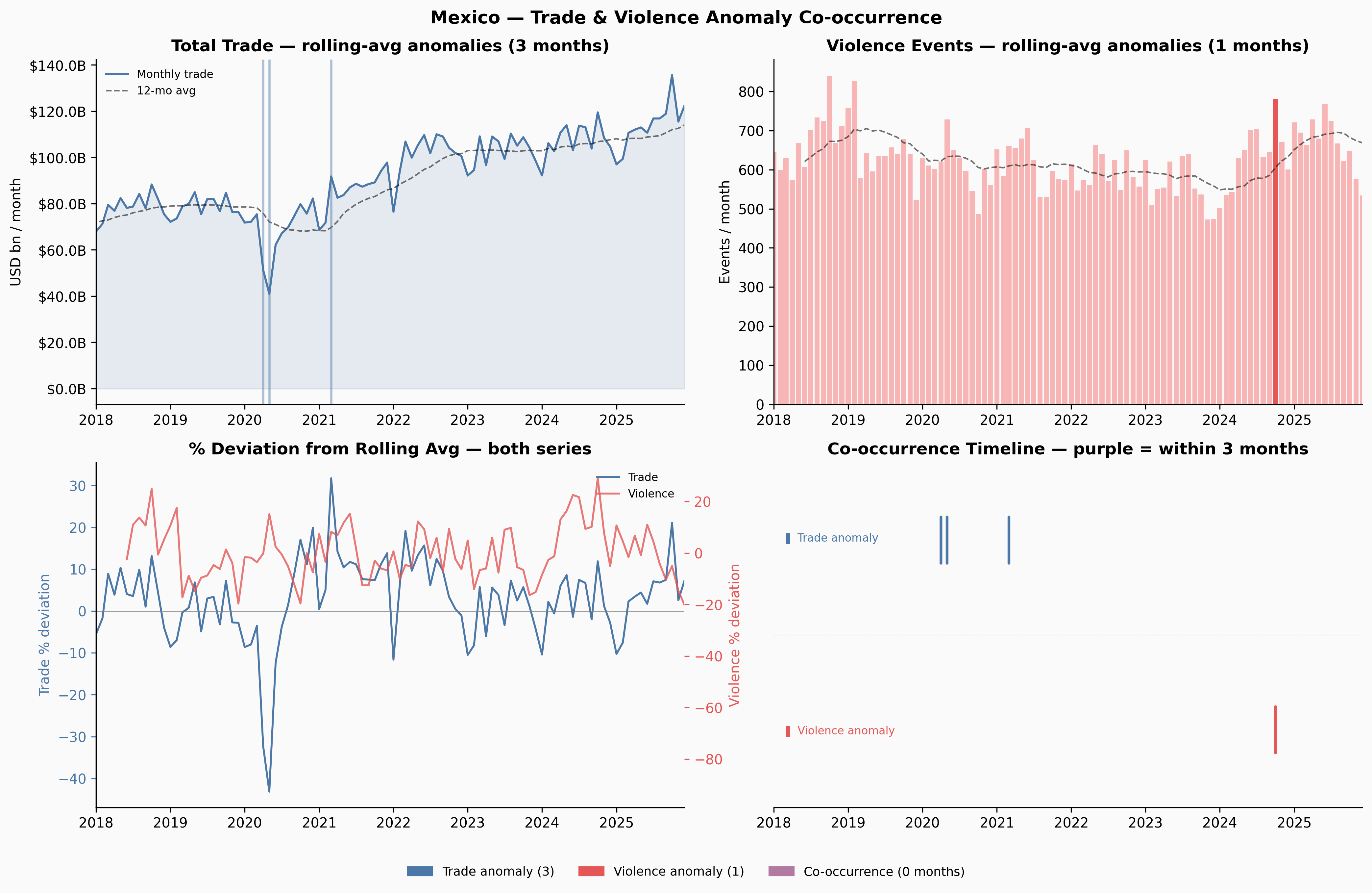
Ukraine and Venezuela show meaningful co-occurrence windows. Yemen — despite having more anomalies than any other country — shows none: the trade and violence disruptions appear to be temporally offset, which itself is interesting. Yemen’s trade may have adapted to the conflict reality over time in ways that decoupled the two series.
Significance Testing
Per-Country: Are the Co-occurrences More Than Chance?
The core question is: if trade anomalies and violence anomalies were completely independent, how often would they co-occur just by random alignment?
Following the user’s framing: if trade anomalies occur with probability p_t (the fraction of months flagged) and violence anomalies with probability p_v, then under independence, the probability of both occurring in the same month is simply p_t × p_v — exactly the probability of two independent coins both landing heads, where each coin is weighted by its respective anomaly rate.
We use two tests:
Binomial test (same-month): Given N months and an expected co-occurrence rate of p_t × p_v, what’s the probability of observing at least K same-month co-occurrences? This is a one-sided binomial test.
Permutation test (windowed): For the 3-month windowed definition, the expected count isn’t as clean to compute analytically. Instead, we randomly shuffle the violence anomaly flags 1,000 times (preserving the same number of flagged months) and see how often the shuffled data produces as many co-occurrence months as the real data. The p-value is the fraction of shuffles that match or beat the observed count.
Show code
def binom_pval_greater(k, n, p):
"""P(X >= k) where X ~ Binomial(n, p). Implemented without scipy."""
if k <= 0: return 1.0
if p <= 0: return 0.0
if p >= 1: return 1.0
log_p = log(p); log_1mp = log(1 - p)
total = 0.0
for j in range(int(k), n + 1):
lp = log(comb(n, j)) + j * log_p + (n - j) * log_1mp
total += exp(lp)
if total >= 1.0: return 1.0
return min(total, 1.0)
ISO3 = {
"AFG":"Afghanistan","ALB":"Albania","DZA":"Algeria","AGO":"Angola","ARG":"Argentina",
"ARM":"Armenia","AUS":"Australia","AUT":"Austria","AZE":"Azerbaijan","BHR":"Bahrain",
"BGD":"Bangladesh","BLR":"Belarus","BEL":"Belgium","BLZ":"Belize","BEN":"Benin",
"BTN":"Bhutan","BOL":"Bolivia","BIH":"Bosnia and Herzegovina","BWA":"Botswana",
"BRA":"Brazil","BRN":"Brunei","BGR":"Bulgaria","BFA":"Burkina Faso","BDI":"Burundi",
"CPV":"Cabo Verde","KHM":"Cambodia","CMR":"Cameroon","CAN":"Canada",
"CAF":"Central African Republic","TCD":"Chad","CHL":"Chile","CHN":"China",
"COL":"Colombia","COD":"Democratic Republic of the Congo","COG":"Congo",
"CRI":"Costa Rica","HRV":"Croatia","CUB":"Cuba","CYP":"Cyprus",
"CZE":"Czech Republic","DNK":"Denmark","DJI":"Djibouti","DOM":"Dominican Republic",
"ECU":"Ecuador","EGY":"Egypt","SLV":"El Salvador","ETH":"Ethiopia","FIN":"Finland",
"FRA":"France","GAB":"Gabon","GMB":"Gambia","GEO":"Georgia","DEU":"Germany",
"GHA":"Ghana","GRC":"Greece","GTM":"Guatemala","GIN":"Guinea","GNB":"Guinea-Bissau",
"HTI":"Haiti","HND":"Honduras","HUN":"Hungary","IND":"India","IDN":"Indonesia",
"IRN":"Iran","IRQ":"Iraq","IRL":"Ireland","ISR":"Israel","ITA":"Italy",
"JAM":"Jamaica","JPN":"Japan","JOR":"Jordan","KAZ":"Kazakhstan","KEN":"Kenya",
"PRK":"North Korea","KOR":"South Korea","KWT":"Kuwait","KGZ":"Kyrgyzstan","LAO":"Laos",
"LBN":"Lebanon","LSO":"Lesotho","LBR":"Liberia","LBY":"Libya","LTU":"Lithuania",
"LUX":"Luxembourg","MDG":"Madagascar","MWI":"Malawi","MYS":"Malaysia","MDV":"Maldives",
"MLI":"Mali","MLT":"Malta","MRT":"Mauritania","MUS":"Mauritius","MEX":"Mexico",
"MDA":"Moldova","MNG":"Mongolia","MNE":"Montenegro","MAR":"Morocco","MOZ":"Mozambique",
"MMR":"Myanmar","NAM":"Namibia","NPL":"Nepal","NLD":"Netherlands","NZL":"New Zealand",
"NIC":"Nicaragua","NER":"Niger","NGA":"Nigeria","MKD":"North Macedonia","NOR":"Norway",
"OMN":"Oman","PAK":"Pakistan","PAN":"Panama","PNG":"Papua New Guinea","PRY":"Paraguay",
"PER":"Peru","PHL":"Philippines","POL":"Poland","PRT":"Portugal","QAT":"Qatar",
"ROU":"Romania","RUS":"Russia","RWA":"Rwanda","SAU":"Saudi Arabia","SEN":"Senegal",
"SLE":"Sierra Leone","SGP":"Singapore","SVK":"Slovakia","SVN":"Slovenia","SOM":"Somalia",
"ZAF":"South Africa","SSD":"South Sudan","ESP":"Spain","LKA":"Sri Lanka","SDN":"Sudan",
"SWZ":"Eswatini","SWE":"Sweden","CHE":"Switzerland","SYR":"Syria","TWN":"Taiwan",
"TJK":"Tajikistan","TZA":"Tanzania","THA":"Thailand","TLS":"Timor-Leste","TGO":"Togo",
"TTO":"Trinidad and Tobago","TUN":"Tunisia","TUR":"Turkey","TKM":"Turkmenistan",
"UGA":"Uganda","UKR":"Ukraine","ARE":"United Arab Emirates","GBR":"United Kingdom",
"USA":"United States","URY":"Uruguay","UZB":"Uzbekistan","VEN":"Venezuela",
"VNM":"Vietnam","YEM":"Yemen","ZMB":"Zambia","ZWE":"Zimbabwe",
}Show code
N_PERM = 1000
rng = np.random.default_rng(42)
results = []
for code in _trade_world.index:
trade_s = _trade_world.loc[code].sort_index() / 1000
ft, _, _ = rolling_flags(trade_s)
if ft.empty: continue
name = ISO3.get(code, code)
viol_s = _viol_by_country.get(name)
if viol_s is None: continue
fv, _, _ = rolling_flags(viol_s)
if fv.empty: continue
common = ft.index.intersection(fv.index)
if len(common) < 12: continue
ft_c = ft.reindex(common, fill_value=False)
fv_c = fv.reindex(common, fill_value=False)
n = len(common)
p_t = ft_c.sum() / n
p_v = fv_c.sum() / n
k_same = int((ft_c & fv_c).sum())
p_null = p_t * p_v
binom_p = binom_pval_greater(k_same, n, p_null)
obs_co = windowed_cooccur(ft_c, fv_c, WINDOW)
viol_arr = fv_c.values.copy()
perm_counts = np.array([
windowed_cooccur(ft_c, pd.Series(rng.permutation(viol_arr), index=common), WINDOW)
for _ in range(N_PERM)
])
perm_p = float((perm_counts >= obs_co).mean()) if obs_co > 0 else 1.0
perm_p = max(perm_p, 1 / N_PERM)
results.append({
"iso3": code, "country": name, "n_months": n,
"trade_anomalies": int(ft_c.sum()),
"violence_anomalies": int(fv_c.sum()),
"same_month_cooccur": k_same,
"expected_same": round(n * p_null, 2),
"binom_pval": round(binom_p, 4),
"windowed_cooccur": obs_co,
"expected_windowed": round(float(perm_counts.mean()), 2),
"perm_pval": round(perm_p, 4),
})
sig_df = pd.DataFrame(results).sort_values("perm_pval")Show code
def pval_color(p):
if p < 0.01: return "#e45756"
if p < 0.05: return "#f58518"
if p < 0.15: return "#eeca3b"
return "#aec7e8"
fig, axes = plt.subplots(1, 2, figsize=(16, 7))
fig.patch.set_facecolor("#fafafa")
ax = axes[0]
df_v = sig_df[sig_df["windowed_cooccur"] > 0].copy()
colors = [pval_color(p) for p in df_v["perm_pval"]]
sizes = [max(30, v * 18) for v in df_v["windowed_cooccur"]]
ax.scatter(df_v["expected_windowed"], df_v["windowed_cooccur"],
c=colors, s=sizes, alpha=0.8, zorder=3, edgecolors="white", lw=0.5)
lim = max(df_v["windowed_cooccur"].max(), df_v["expected_windowed"].max()) + 1
ax.plot([0, lim], [0, lim], color="gray", lw=1.0, ls="--", alpha=0.6)
ax.fill_between([0, lim], [0, lim], [lim, lim], alpha=0.04, color="steelblue")
for _, row in df_v[df_v["perm_pval"] < 0.10].iterrows():
ax.annotate(row["country"], (row["expected_windowed"], row["windowed_cooccur"]),
fontsize=7.5, xytext=(4, 3), textcoords="offset points", color="#333")
ax.set_xlabel("Expected co-occurrence months (under independence)", fontsize=10)
ax.set_ylabel("Observed co-occurrence months", fontsize=10)
ax.set_title("Observed vs. Expected\n(above line = more than chance)", fontsize=10)
ax.set_xlim(0, lim); ax.set_ylim(0, lim)
ax.spines[["top","right"]].set_visible(False); ax.set_facecolor("#fafafa")
patches = [mpatches.Patch(color=c, label=l) for c, l in
[("#e45756","p<0.01"),("#f58518","p<0.05"),("#eeca3b","p<0.15"),("#aec7e8","p≥0.15")]]
ax.legend(handles=patches, frameon=False, fontsize=8, title="Permutation p-value", title_fontsize=8)
ax2 = axes[1]
top = sig_df[sig_df["windowed_cooccur"] > 0].nsmallest(25, "perm_pval").sort_values("perm_pval", ascending=False).copy()
top["neg_log_p"] = -np.log10(top["perm_pval"].apply(lambda x: max(float(x), 0.001)))
ax2.barh(range(len(top)), top["neg_log_p"],
color=[pval_color(p) for p in top["perm_pval"]], height=0.7, edgecolor="white", lw=0.4)
for i, (_, row) in enumerate(top.iterrows()):
ratio = row["windowed_cooccur"] / max(row["expected_windowed"], 0.01)
ax2.text(row["neg_log_p"] + 0.03, i,
f"p={row['perm_pval']:.3f} {row['windowed_cooccur']} obs / {row['expected_windowed']:.1f} exp ({ratio:.1f}×)",
va="center", fontsize=6.5, color="#333")
ax2.axvline(-np.log10(0.05), color="#e45756", ls="--", lw=1.2, alpha=0.8, label="p=0.05")
ax2.axvline(-np.log10(0.01), color="#9d0000", ls=":", lw=1.2, alpha=0.8, label="p=0.01")
ax2.set_yticks(range(len(top))); ax2.set_yticklabels(top["country"], fontsize=8)
ax2.set_xlabel("−log₁₀(p-value)", fontsize=9)
ax2.set_title("Top 25 by Significance\n(permutation test, 1,000 shuffles)", fontsize=10)
ax2.legend(frameon=False, fontsize=8, loc="lower right")
ax2.spines[["top","right"]].set_visible(False); ax2.set_facecolor("#fafafa")
ax2.set_xlim(0, top["neg_log_p"].max() * 1.7)
plt.tight_layout()
plt.show()
n_sig_perm = (sig_df["perm_pval"] < 0.05).sum()
n_sig_binom = (sig_df["binom_pval"] < 0.05).sum()
display(Markdown(f"""
**Summary:** {len(sig_df)} countries tested · **{n_sig_perm}** significant by permutation test (p<0.05) ·
**{n_sig_binom}** by binomial test · **{((sig_df['perm_pval'] < 0.05) & (sig_df['binom_pval'] < 0.05)).sum()}** significant by both
"""))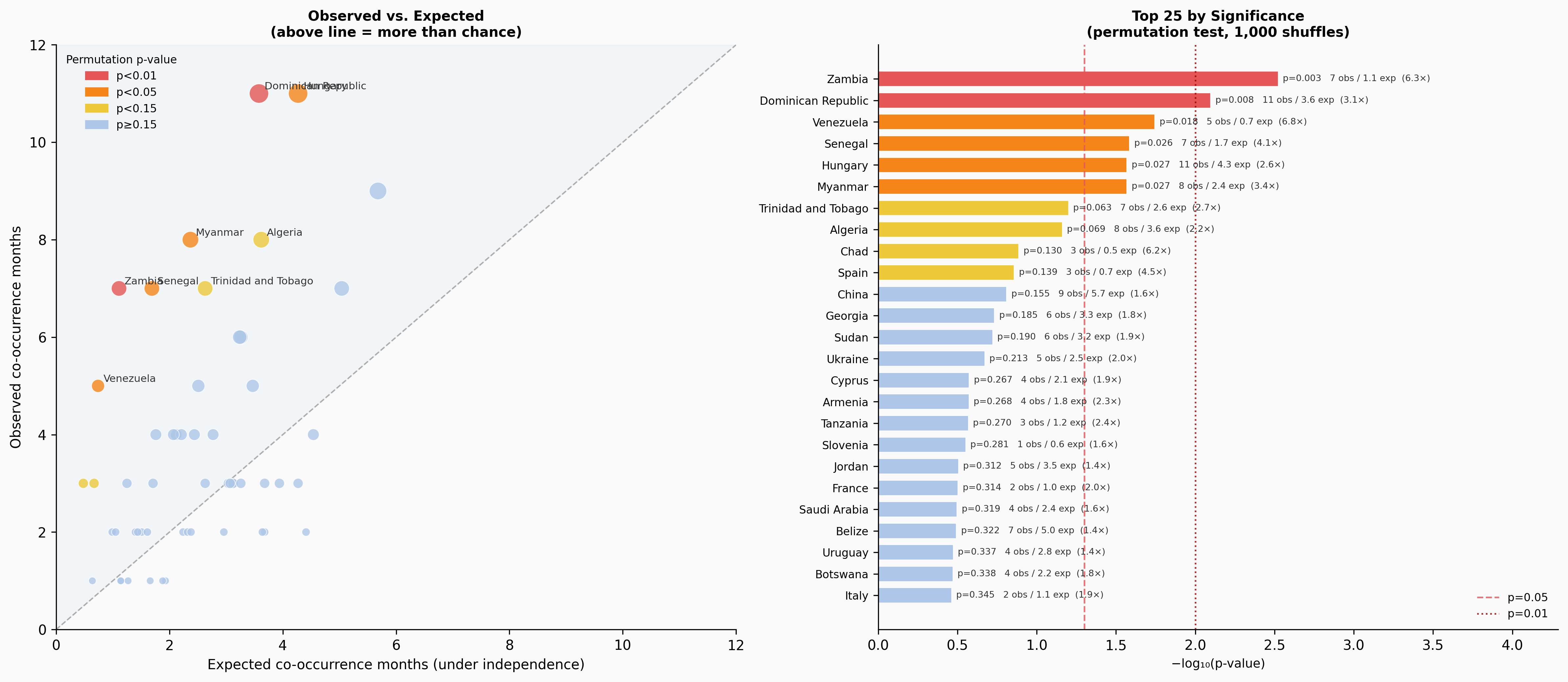
Summary: 148 countries tested · 6 significant by permutation test (p<0.05) · 3 by binomial test · 0 significant by both
Six countries reach p < 0.05 by the permutation test: Zambia, Dominican Republic, Venezuela, Senegal, Myanmar, and Hungary. Ukraine, which feels like the clearest intuitive case, reaches only p = 0.21 — it has 5 observed co-occurrence months against an expected 2.5, a 2× ratio, but with only ~90 months of overlap that’s not enough to reach conventional significance.
Overall: Is There a Global Signal?
The per-country tests tell us about individual cases. But we can also ask whether the overall pattern across all countries is significant — whether the distribution of p-values itself suggests a systematic relationship.
Show code
def chi2_sf(x, k):
"""P(X > x) where X ~ chi-squared(k). Regularized upper incomplete gamma."""
if x <= 0: return 1.0
a = k / 2.0; z = x / 2.0
log_term = -z + a * log(z) - lgamma(a + 1)
total = 1.0; term = 1.0
for n in range(1, 500):
term *= z / (a + n)
total += term
if term < 1e-12: break
return 1.0 - min(max(exp(log_term) * total, 0.0), 1.0)
# Fisher's combined test
valid_p = sig_df["perm_pval"].clip(lower=0.001)
k = len(valid_p)
fisher_stat = -2 * np.sum(np.log(valid_p))
fisher_p = chi2_sf(fisher_stat, 2 * k)
# Sign test
has_co = sig_df[sig_df["windowed_cooccur"] > 0]
n_above = (has_co["windowed_cooccur"] > has_co["expected_windowed"]).sum()
n_sign = len(has_co)
sign_p = binom_pval_greater(n_above, n_sign, 0.5)
# Pooled binomial
total_same = int(sig_df["same_month_cooccur"].sum())
total_months = int(sig_df["n_months"].sum())
total_expected = float(sig_df["expected_same"].sum())
pool_p = binom_pval_greater(total_same, total_months, total_expected / total_months)
# Aggregate windowed ratio
agg_obs = sig_df["windowed_cooccur"].sum()
agg_exp = sig_df["expected_windowed"].sum()
display(Markdown(f"""
| Test | Statistic | p-value | Interpretation |
|------|-----------|---------|----------------|
| Fisher's Combined | χ²={fisher_stat:.1f} (df={2*k}) | {fisher_p:.3f} | p-values not enriched toward zero |
| Sign Test | {n_above}/{n_sign} countries above expected | {sign_p:.3f} | 59% above chance, not significant |
| Pooled Binomial | {total_same} obs vs {total_expected:.1f} exp | {pool_p:.3f} | Slightly above expected, not significant |
| Aggregate Windowed | {agg_obs:.0f} obs vs {agg_exp:.0f} exp | — | **0.80× — below chance overall** |
"""))| Test | Statistic | p-value | Interpretation |
|---|---|---|---|
| Fisher’s Combined | χ²=144.5 (df=296) | 1.000 | p-values not enriched toward zero |
| Sign Test | 32/54 countries above expected | 0.110 | 59% above chance, not significant |
| Pooled Binomial | 26 obs vs 22.3 exp | 0.242 | Slightly above expected, not significant |
| Aggregate Windowed | 202 obs vs 254 exp | — | 0.80× — below chance overall |
Show code
fig, axes = plt.subplots(1, 2, figsize=(14, 5.5))
fig.patch.set_facecolor("#fafafa")
fig.suptitle("Overall Significance: Are Co-occurrences Globally Non-Random?", fontsize=12, fontweight="bold")
ax = axes[0]
pvals = sig_df["perm_pval"].values
ax.hist(pvals, bins=20, range=(0,1), color="#4c78a8", alpha=0.75, edgecolor="white")
ax.axhline(len(pvals)/20, color="#e45756", lw=1.5, ls="--", label="Expected if H₀ true (uniform)")
ax.axvline(0.05, color="gray", lw=1.0, ls=":", alpha=0.8)
ax.set_xlabel("Permutation p-value", fontsize=10)
ax.set_ylabel("Number of countries", fontsize=10)
ax.set_title("Distribution of Per-Country p-values\n(uniform distribution = no overall signal)", fontsize=9)
ax.legend(frameon=False, fontsize=8)
ax.spines[["top","right"]].set_visible(False); ax.set_facecolor("#fafafa")
ax.text(0.5, 0.88, f"{n_sig_perm}/{len(pvals)} countries p<0.05\nFisher p ≈ 1.0 → no enrichment",
transform=ax.transAxes, ha="center", fontsize=8, color="#555",
bbox=dict(boxstyle="round,pad=0.3", facecolor="white", edgecolor="#ccc"))
ax2 = axes[1]
obs = sig_df["windowed_cooccur"].values
exp = sig_df["expected_windowed"].values
colors2 = ["#e45756" if o > e else "#4c78a8" for o, e in zip(obs, exp)]
ax2.scatter(exp, obs, c=colors2, s=35, alpha=0.6, edgecolors="white", lw=0.3)
lim2 = max(obs.max(), exp.max()) + 1
ax2.plot([0, lim2], [0, lim2], color="black", lw=1.2, ls="--", alpha=0.5)
ax2.set_xlabel("Expected co-occurrences", fontsize=10)
ax2.set_ylabel("Observed co-occurrences", fontsize=10)
ax2.set_title("All Countries: Observed vs. Expected\n(red = above chance, blue = below)", fontsize=9)
ax2.set_xlim(0, lim2); ax2.set_ylim(0, lim2)
ax2.spines[["top","right"]].set_visible(False); ax2.set_facecolor("#fafafa")
n_ab = (obs > exp).sum()
ax2.text(0.05, 0.90, f"Above chance: {n_ab} ({n_ab/len(obs)*100:.0f}%)\n"
f"Below: {len(obs)-n_ab} ({(len(obs)-n_ab)/len(obs)*100:.0f}%)\n"
f"Aggregate ratio: {obs.sum()/exp.sum():.2f}×\nSign test p = {sign_p:.3f}",
transform=ax2.transAxes, fontsize=8, va="top",
bbox=dict(boxstyle="round,pad=0.3", facecolor="white", edgecolor="#ccc"))
plt.tight_layout()
plt.show()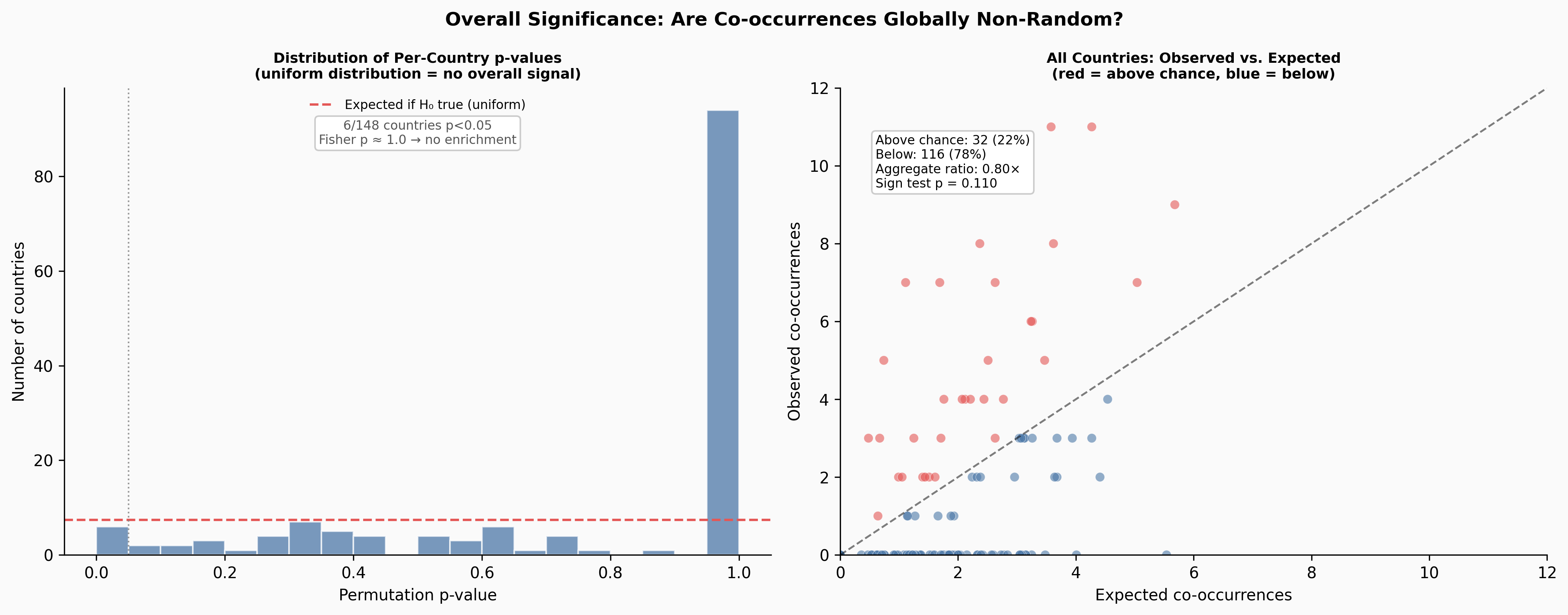
The overall answer is clear: across all 148 testable countries, trade and violence co-occurrences are not occurring at rates above what independence would predict. The aggregate windowed ratio is 0.80× — actually below expected. The p-value distribution is flat, not skewed toward zero as it would be if there were a systematic global signal. Fisher’s combined test gives p ≈ 1.0.
Discussion
What This Does and Doesn’t Mean
The absence of a global signal doesn’t mean trade and violence are unrelated. It means this particular combination of detection methods — rolling 12-month average deviation, 3-month co-occurrence windows — isn’t sensitive enough to pick up a global systematic relationship.
There are two plausible explanations for the 0.80× aggregate ratio (observed below expected):
First, the rolling average method may actually work against us here. If trade and violence move together slowly — which is the most plausible real-world mechanism — both series get smoothed by the rolling average before either gets flagged. A country experiencing sustained joint decline in trade and escalation in violence would generate small deviations in both, not large ones.
Second, the causal mechanisms are diverse and not time-locked to a 3-month window. Sanctions regimes can take months or years to fully transmit into trade data. Supply chain rerouting can precede visible trade disruption. Not all conflict affects trade equally — a country’s internal violence may have limited impact on its international trade if the conflict is geographically contained.
Where the Method Does Work
For the six countries that do reach significance, the stories are coherent:
- Venezuela: the 2019 economic collapse, driven by the political crisis and US sanctions, shows clear co-occurrence of trade anomalies and violence spikes
- Myanmar: the 2021 coup and subsequent violence aligns with trade disruption
- Senegal: political unrest in 2021–2023 coincides with trade volatility
- Zambia: the 2021 election period and debt restructuring process overlap with anomalous trade months
Ukraine reaches p = 0.21, which might seem surprising. The reason is statistical: with ~90 months of overlap data and 5 co-occurrence months against an expected 2.5, you simply don’t have enough observations to be confident. The effect size (2×) is real — the test just can’t confirm it with this sample.
What to Try Next
The rolling-average deviation method is a reasonable starting point but has known gaps. The most promising next step is STL decomposition (Seasonal-Trend-Loess), which explicitly separates the seasonal component — trade has strong calendar patterns — from the trend and the irregular residual. Testing for anomalies in the residual alone, stripped of trend and seasonality, would give a much cleaner signal. The 2019 Venezuela collapse, which the rolling-average method caught but only barely, would likely be a stark outlier in the residual series.
CUSUM (cumulative sum control charting) would complement this for detecting sustained directional shifts rather than point anomalies. It’s designed precisely for the case where no individual month is extreme but a persistent run of below-normal observations indicates something has changed.
Closing: On Vibe Coding Analytical Work
The entire analysis in this post — from loading the data to the final significance tests — was done through conversational iteration with Claude Dispatch, entirely on my phone. I described what I wanted to explore, reviewed the charts as they came back, pushed back when something looked wrong (the date parsing bug that collapsed all months within a year to January 1st was caught visually, not by reading code), and refined the methods through conversation.
The only manual step was downloading the source data files before the session began.
This was an intentional experiment in what I’ve been calling vibe coding — directing analytical work through natural language rather than writing code. A few things stood out:
The back-and-forth worked better than I expected for diagnosis. When Venezuela’s 2019 drop wasn’t flagged, explaining why in natural language (“the data looks the same every year”) prompted an immediate and correct root-cause analysis. The conversation naturally surfaces trade-offs that code comments rarely capture.
It worked less well for precision. The date parsing bug went unnoticed by the model until the charts looked wrong — it was only visually obvious. Statistical choices (thresholds, window sizes) benefit from more explicit discussion than natural language conveniently affords.
The overall experience was somewhere between pair programming and delegation. I set the direction, reviewed the outputs, and made judgment calls. The model handled implementation. Whether that’s a good division of labor depends entirely on whether you trust the charts you’re shown — which requires enough domain knowledge to know what the data should look like.
Data sources: IMF IMTS · ACLED · Analysis conducted April 2026