import re
import math
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import matplotlib.ticker as mtick
from pathlib import Path
from IPython.display import Markdown, display
plt.rcParams.update({
"figure.dpi": 150,
"axes.spines.top": False,
"axes.spines.right": False,
"font.size": 9,
"axes.titlesize": 11,
"axes.titleweight": "bold",
"figure.facecolor": "#fafafa",
"axes.facecolor": "#fafafa",
})
_DIR = Path(".")
_CSV = Path(
"../2026-04-17-imts-exploratory/"
"dataset_2026-04-19T01_51_08.510445992Z_DEFAULT_INTEGRATION_IMF.STA_IMTS_1.0.0.csv"
)
TARGET = ['UKR', 'VEN', 'YEM', 'MEX', 'DNK']
INDICATOR = 'XG_FOB_USD' # goods exports, FOB, USD millions
COUNTRY_NAMES = {
'UKR': 'Ukraine', 'VEN': 'Venezuela', 'YEM': 'Yemen',
'MEX': 'Mexico', 'DNK': 'Denmark',
}
# ISO 3166-1 alpha-3 → display name (hardcoded; no pycountry)
PARTNER_NAMES = {
'USA': 'United States', 'CHN': 'China', 'DEU': 'Germany',
'RUS': 'Russia', 'GBR': 'United Kingdom', 'FRA': 'France',
'ITA': 'Italy', 'ESP': 'Spain', 'NLD': 'Netherlands',
'BEL': 'Belgium', 'POL': 'Poland', 'TUR': 'Turkey',
'IND': 'India', 'JPN': 'Japan', 'KOR': 'South Korea',
'BRA': 'Brazil', 'MEX': 'Mexico', 'CAN': 'Canada',
'AUS': 'Australia', 'ZAF': 'South Africa', 'EGY': 'Egypt',
'SAU': 'Saudi Arabia', 'ARE': 'UAE', 'IRN': 'Iran',
'IRQ': 'Iraq', 'JOR': 'Jordan', 'KWT': 'Kuwait',
'OMN': 'Oman', 'COL': 'Colombia', 'ARG': 'Argentina',
'CUB': 'Cuba', 'PAN': 'Panama', 'VEN': 'Venezuela',
'CHL': 'Chile', 'PER': 'Peru', 'ECU': 'Ecuador',
'UKR': 'Ukraine', 'BGR': 'Bulgaria', 'ROU': 'Romania',
'HUN': 'Hungary', 'CZE': 'Czech Republic', 'SVK': 'Slovakia',
'SVN': 'Slovenia', 'HRV': 'Croatia', 'SRB': 'Serbia',
'BLR': 'Belarus', 'MDA': 'Moldova', 'GEO': 'Georgia',
'ARM': 'Armenia', 'AZE': 'Azerbaijan', 'KAZ': 'Kazakhstan',
'UZB': 'Uzbekistan', 'SWE': 'Sweden', 'NOR': 'Norway',
'FIN': 'Finland', 'DNK': 'Denmark', 'CHE': 'Switzerland',
'AUT': 'Austria', 'GRC': 'Greece', 'PRT': 'Portugal',
'ISR': 'Israel', 'MAR': 'Morocco', 'NGA': 'Nigeria',
'KEN': 'Kenya', 'LBN': 'Lebanon', 'LTU': 'Lithuania',
'LVA': 'Latvia', 'EST': 'Estonia', 'SGP': 'Singapore',
'MYS': 'Malaysia', 'THA': 'Thailand', 'IDN': 'Indonesia',
'VNM': 'Vietnam', 'PHL': 'Philippines', 'PAK': 'Pakistan',
'BGD': 'Bangladesh', 'LUX': 'Luxembourg', 'NZL': 'New Zealand',
'TWN': 'Taiwan', 'HKG': 'Hong Kong', 'LBY': 'Libya',
'DZA': 'Algeria', 'TUN': 'Tunisia', 'SOM': 'Somalia',
'DJI': 'Djibouti', 'ETH': 'Ethiopia', 'SDN': 'Sudan',
'YEM': 'Yemen', 'ABW': 'Aruba', 'MWI': 'Malawi',
'CIV': "Côte d'Ivoire", 'SEN': 'Senegal', 'GHA': 'Ghana',
'CMR': 'Cameroon', 'AGO': 'Angola', 'MOZ': 'Mozambique',
'TZA': 'Tanzania', 'UGA': 'Uganda',
}Predicting Trade: Anomaly Detection via One-Step-Ahead Forecasting (Part 1)
Starting with the simplest possible baseline: a 12-month moving average
trade
forecasting
anomaly-detection
time-series
NoteA note on how this was made
This post is part of an ongoing series on IMF International Merchandise Trade Statistics (IMTS) data, built entirely through vibe coding in Claude Dispatch. I describe the analysis I want; Claude writes and runs the code; I review the results and push back. The analysis is what emerged from that back-and-forth.
The core idea
In the previous post, we looked at trade data as a potential signal for political disruption — comparing raw anomalies in trade volume against ACLED political violence events. The approach worked for some countries (Ukraine, Venezuela) and not for others, partly because “anomaly” was defined in a fairly naive way.
This post tries something a bit more principled: instead of just flagging unusual values, we predict what the next month’s trade should look like, and treat large prediction errors as anomalies. The intuition is clean — if your model is good, anything it fails to predict is genuinely surprising. If it’s bad, its failures are just noise.
To make that logic work, you need model quality and anomaly interpretability to be linked. The better the model, the more you can trust its residuals as signals. The worse the model, the harder it is to know whether a large residual is a real structural break or just the model being wrong in a boring way.
This post intentionally starts with the worst reasonable baseline: a 12-month moving average. It’s not a good model. It doesn’t handle trends. It doesn’t handle seasonality. It lags behind reality by construction. We’re establishing a floor here — a benchmark whose limitations will motivate something better in the next post.
The question we’ll explore: even with a bad model, what do the residuals look like for countries with known structural breaks?
Setup
Data
The IMF IMTS flat file contains 402,443 rows covering 227 reporting countries and 108 monthly periods (January 2017 through December 2025). Each row is a unique REPORTER.INDICATOR.PARTNER.FREQ combination; the indicator XG_FOB_USD is goods exports in USD millions, valued FOB.
For this analysis we’re working with five countries: Ukraine, Venezuela, Yemen, Mexico, and Denmark. They were chosen to span a range of stories — two countries with severe conflict-era disruptions (Ukraine, Yemen), one with a prolonged economic collapse (Venezuela), one large stable emerging-market exporter (Mexico), and one small stable high-income exporter as a control (Denmark).
Show code
all_cols = pd.read_csv(_CSV, nrows=0).columns.tolist()
monthly_cols = [c for c in all_cols if re.match(r'^\d{4}-M\d{2}$', c)]
# Critical: parse "2017-M01" → "2017-01-01" (not "2017-M01-01")
_dates = pd.to_datetime([c.replace('-M', '-') + '-01' for c in monthly_cols])
raw = pd.read_csv(_CSV, usecols=['SERIES_CODE'] + monthly_cols, dtype=str)
parts = raw['SERIES_CODE'].str.split('.', n=3, expand=True)
parts.columns = ['reporter', 'indicator', 'partner', 'freq']
df = pd.concat([parts, raw[monthly_cols]], axis=1)
df = df[
(df['freq'] == 'M') &
(df['reporter'].isin(TARGET)) &
(df['indicator'] == INDICATOR)
].copy()
df[monthly_cols] = df[monthly_cols].apply(pd.to_numeric, errors='coerce')After loading, we melt the wide-format monthly columns into a long format and compute each partner’s share of total exports. The world aggregate (partner code G001) is our denominator. We keep only bilateral partners with real ISO3 country codes — filtering out the IMF’s group codes like G998 (not allocated) and GX-prefixed regional aggregates.
Show code
rows = []
for c in TARGET:
sub = bilateral[bilateral['reporter'] == c]
w = world[world['reporter'] == c]
rows.append({
'Country': COUNTRY_NAMES[c],
'Partners': sub['partner'].nunique(),
'Months': sub['date'].nunique(),
'Date range': (
f"{sub['date'].min().strftime('%b %Y')} – "
f"{sub['date'].max().strftime('%b %Y')}"
),
'Avg monthly exports (USD M)': f"{w['world_total'].mean():,.0f}",
})
summary_df = pd.DataFrame(rows)
display(Markdown(summary_df.to_markdown(index=False)))| Country | Partners | Months | Date range | Avg monthly exports (USD M) |
|---|---|---|---|---|
| Ukraine | 202 | 108 | Jan 2017 – Dec 2025 | 3,832 |
| Venezuela | 141 | 108 | Jan 2017 – Dec 2025 | 1,098 |
| Yemen | 76 | 108 | Jan 2017 – Dec 2025 | 9 |
| Mexico | 202 | 108 | Jan 2017 – Dec 2025 | 43,389 |
| Denmark | 205 | 108 | Jan 2017 – Dec 2025 | 10,078 |
Trade partner composition
Before modeling anything, it’s worth visualising the underlying structure we’re trying to predict. For each country we find the top 6 bilateral trade partners by average export share, then plot their shares as a stacked area chart over time.
A few things to notice before we start predicting:
- Ukraine has a diverse mix that visibly reshuffles around 2022. Russia’s share collapses; Poland and China pick up.
- Venezuela is heavily concentrated in a few destinations, with the United States dominant early and declining sharply after 2019.
- Yemen has sparse, erratic data — small absolute volumes and a few opportunistic partners filling the gap after conflict disruption.
- Mexico shows extreme concentration in the United States, stable and predictable year after year.
- Denmark is well-diversified across European neighbors and the United States, with very smooth dynamics.
These patterns set expectations for the model. Mexico and Denmark should be easy to forecast — the patterns are stable. Ukraine, Venezuela, and Yemen will be harder.
Show code
N_TOP = 6
top_partners = {}
for country in TARGET:
sub = bilateral[bilateral['reporter'] == country]
partner_avg = (
sub.groupby('partner')
.agg(
avg_share=('share', 'mean'),
n_months=('share', lambda x: (x > 0).sum())
)
.reset_index()
)
# Require at least 12 months of non-zero trade to be considered
partner_avg = partner_avg[partner_avg['n_months'] >= 12]
top_partners[country] = (
partner_avg.nlargest(N_TOP, 'avg_share')['partner'].tolist()
)Show code
PALETTE = [
'#1f77b4','#ff7f0e','#2ca02c','#d62728',
'#9467bd','#8c564b','#e377c2','#7f7f7f'
]
full_date_range = pd.date_range(start=_dates.min(), end=_dates.max(), freq='MS')
fig, axes = plt.subplots(5, 1, figsize=(11, 22), constrained_layout=True)
fig.suptitle(
"Export Partner Composition — Top 6 Bilateral Partners",
fontsize=13, fontweight='bold', y=1.01
)
for ax, country in zip(axes, TARGET):
sub = bilateral[bilateral['reporter'] == country]
partners = top_partners[country]
share_data = {}
for p in partners:
pdata = (
sub[sub['partner'] == p]
.set_index('date')['share']
.reindex(full_date_range)
.fillna(0)
)
share_data[PARTNER_NAMES.get(p, p)] = pdata
share_df = pd.DataFrame(share_data, index=full_date_range)
ax.stackplot(
share_df.index, share_df.T.values,
labels=share_df.columns,
colors=PALETTE[:len(partners)], alpha=0.80
)
ax.set_title(COUNTRY_NAMES[country], loc='left', pad=6)
ax.set_ylabel('Share of exports', fontsize=8)
ax.yaxis.set_major_formatter(mtick.PercentFormatter(1.0, decimals=0))
ax.set_xlim(full_date_range[0], full_date_range[-1])
ax.legend(loc='upper right', fontsize=7, ncol=2, framealpha=0.7)
ax.tick_params(labelsize=8)
plt.savefig(_DIR / 'fig_stacked_shares.png', bbox_inches='tight', dpi=150)
plt.show()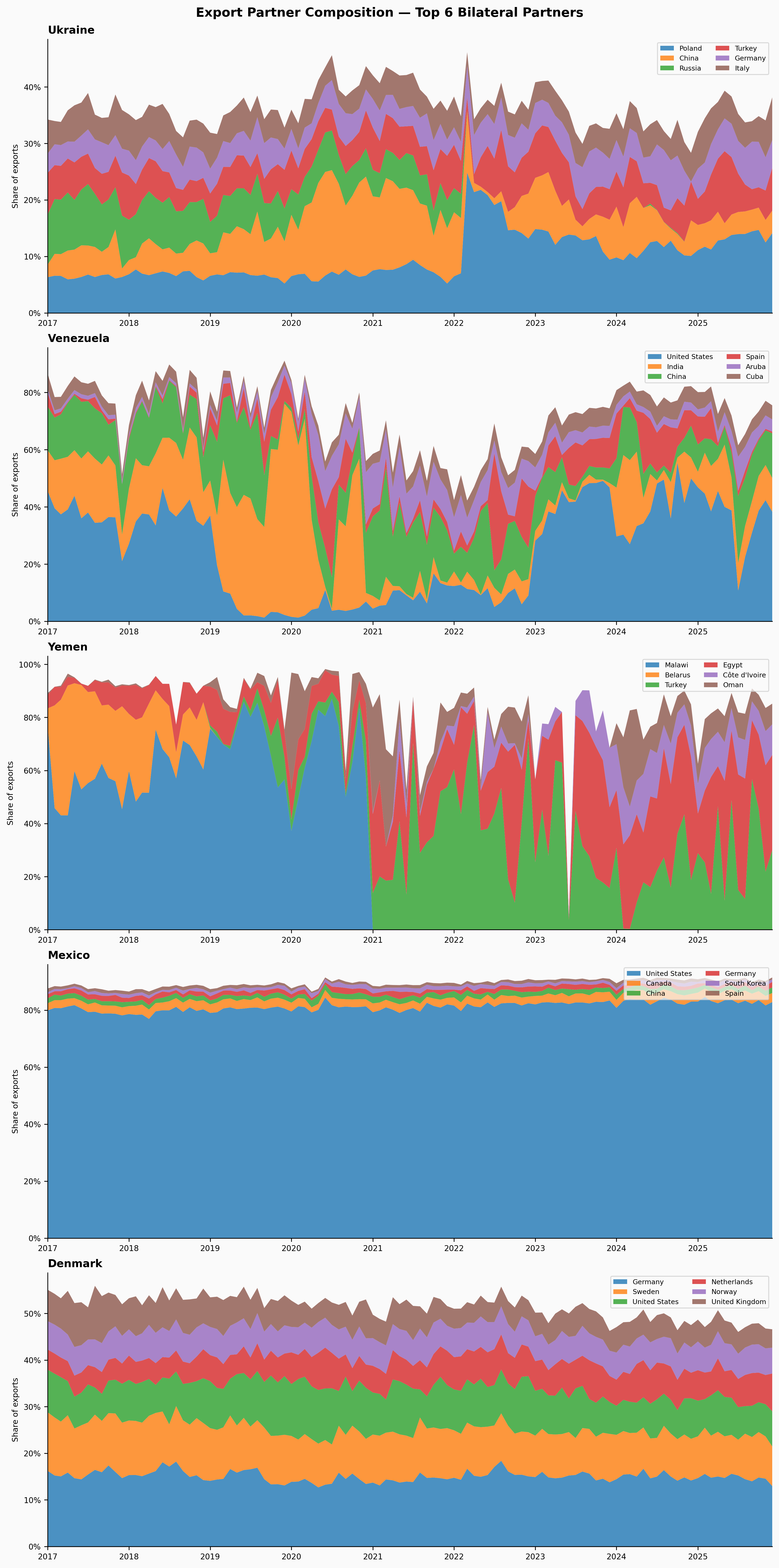
The model: 12-month moving average
The model is as simple as it looks. For each country-partner time series of export shares, we compute a 12-month rolling mean and shift it forward by one period. That shifted value is our one-step-ahead prediction:
\[\hat{s}_t = \frac{1}{12} \sum_{k=1}^{12} s_{t-k}\]
The residual is just actual minus predicted: \(e_t = s_t - \hat{s}_t\).
We need 12 months of history before making any prediction, so the first valid residual is at month 13 of each series. The min_periods=12 argument enforces this — we don’t allow partial windows.
Why is this a bad model? A few reasons:
It can’t follow trends. If a partner’s share is steadily increasing (say, China’s share of Ukraine’s exports over 2022–2024), the MA will persistently underpredict — producing systematically positive residuals that have nothing to do with anomalies.
It doesn’t know about seasonality. Trade patterns often have seasonal cycles. The MA smooths them out and then flags months where seasonality deviates from the average — which is most months.
It reacts slowly. After a genuine structural break, the MA takes 12 months to fully incorporate the new level. During that period, it flags every month as anomalous.
These are features for our purposes, not bugs — they’ll help us understand exactly what a better model needs to do.
Show code
def _safe_std(vals):
"""Sample std, ignoring NaN."""
v = [x for x in vals if x == x] # NaN != NaN
if len(v) < 2:
return float('nan')
mu = sum(v) / len(v)
var = sum((x - mu) ** 2 for x in v) / (len(v) - 1)
return math.sqrt(var)
def _safe_mean(vals):
v = [x for x in vals if x == x]
return sum(v) / len(v) if v else float('nan')
def _safe_mae(vals):
v = [x for x in vals if x == x]
return sum(abs(x) for x in v) / len(v) if v else float('nan')
def _safe_rmse(vals):
v = [x for x in vals if x == x]
return math.sqrt(sum(x ** 2 for x in v) / len(v)) if v else float('nan')
series_results = []
for country in TARGET:
for partner in top_partners[country]:
sub = (
bilateral[
(bilateral['reporter'] == country) &
(bilateral['partner'] == partner)
][['date', 'share']]
.sort_values('date')
)
# Full monthly index for this series
idx = pd.date_range(sub['date'].min(), sub['date'].max(), freq='MS')
share_s = sub.set_index('date')['share'].reindex(idx)
# One-step-ahead prediction: 12-mo rolling mean, shifted 1 period forward
pred_s = share_s.rolling(window=12, min_periods=12).mean().shift(1)
resid_s = share_s - pred_s
resid_vals = resid_s.dropna().tolist()
series_results.append({
'reporter': country,
'partner': partner,
'share': share_s,
'pred': pred_s,
'residual': resid_s,
'mae': _safe_mae(resid_vals),
'rmse': _safe_rmse(resid_vals),
'resid_std': _safe_std(resid_vals),
})How bad is it?
The table below shows mean absolute error (MAE) and root mean squared error (RMSE), both in percentage-point terms, averaged across the top 6 partners for each country. The numbers confirm what we expected from the charts.
Show code
metrics_rows = []
for country in TARGET:
cs = [r for r in series_results if r['reporter'] == country]
maes = [r['mae'] for r in cs if not math.isnan(r['mae'])]
rmses = [r['rmse'] for r in cs if not math.isnan(r['rmse'])]
metrics_rows.append({
'Country': COUNTRY_NAMES[country],
'Avg MAE (pp)': f"{_safe_mean(maes) * 100:.2f}" if maes else '—',
'Avg RMSE (pp)': f"{_safe_mean(rmses) * 100:.2f}" if rmses else '—',
'Fit quality': '★★★★★' if _safe_mean(rmses)*100 < 1 else
'★★★★☆' if _safe_mean(rmses)*100 < 2 else
'★★★☆☆' if _safe_mean(rmses)*100 < 5 else
'★★☆☆☆' if _safe_mean(rmses)*100 < 10 else '★☆☆☆☆'
})
display(Markdown(pd.DataFrame(metrics_rows).to_markdown(index=False)))| Country | Avg MAE (pp) | Avg RMSE (pp) | Fit quality |
|---|---|---|---|
| Ukraine | 1.38 | 1.99 | ★★★★☆ |
| Venezuela | 5.33 | 7.68 | ★★☆☆☆ |
| Yemen | 8.35 | 10.91 | ★☆☆☆☆ |
| Mexico | 0.34 | 0.43 | ★★★★★ |
| Denmark | 0.71 | 0.93 | ★★★★★ |
Mexico and Denmark are nearly predictable by this simple model — partner shares are so stable that even a naive 12-month average tracks them well. Yemen is the worst, with RMSE above 10pp. That’s partly genuine disruption, but it’s also partly that Yemen’s trade data is sparse and erratic at baseline, so the model has nothing stable to learn from.
Anomaly detection
With residuals in hand, we flag months where the absolute residual exceeds 2 standard deviations of the residual distribution for that series. The threshold is computed per series — so a 5pp residual in Yemen (high-noise baseline) means something very different from a 5pp residual in Denmark (low-noise baseline).
Formally: for each country-partner series, we compute \(\sigma\) = sample standard deviation of \(\{e_t\}\), then flag month \(t\) if \(|e_t| > 2\sigma\).
Show code
ANOMALY_THRESHOLD = 2.0
def flag_anomalies(resid_s, threshold=ANOMALY_THRESHOLD):
"""
Returns a boolean Series (same index as resid_s).
True where |residual| > threshold * std(residuals).
NaN residuals are treated as non-anomalous.
"""
valid = resid_s.dropna()
if len(valid) < 10:
return pd.Series(False, index=resid_s.index)
sigma = valid.std()
if sigma == 0 or math.isnan(sigma):
return pd.Series(False, index=resid_s.index)
return resid_s.abs() > threshold * sigmaThe charts below show, for each country and each of its top 6 trade partners: the actual export share (blue), the MA prediction (orange dashed), and anomalous months highlighted in red. Red vertical shading marks the flagged months; red dots mark the actual value at those points.
Ukraine
Ukraine is the clearest case. The Russian invasion in February 2022 restructured trade relationships almost overnight — Russia’s share of Ukrainian exports collapses, Poland’s surges, and Turkey and China grow as alternative corridors. The MA model is completely unprepared for any of this and flags a sustained run of anomalies across multiple partners starting in early 2022.
Show code
def plot_anomaly_country(country, save_path=None):
country_series = [r for r in series_results if r['reporter'] == country]
n = len(country_series)
ncols = 2
nrows = math.ceil(n / ncols)
fig, axes = plt.subplots(
nrows, ncols, figsize=(12, 3.5 * nrows), constrained_layout=True
)
axes_flat = axes.flatten() if n > 1 else [axes]
fig.suptitle(
f"{COUNTRY_NAMES[country]} — Export Share: MA Prediction & Anomalies",
fontsize=12, fontweight='bold'
)
for idx, result in enumerate(country_series):
ax = axes_flat[idx]
share_s = result['share']
pred_s = result['pred']
resid_s = result['residual']
partner = result['partner']
pname = PARTNER_NAMES.get(partner, partner)
is_anom = flag_anomalies(resid_s)
# Align anomaly flags to share index (same index, but reindex to be safe)
anom_aligned = is_anom.reindex(share_s.index).fillna(False)
n_anom = anom_aligned.sum()
ax.plot(share_s.index, share_s.values * 100,
color='#1f77b4', linewidth=1.4, label='Actual share', zorder=3)
ax.plot(pred_s.index, pred_s.values * 100,
color='#ff7f0e', linewidth=1.2, linestyle='--',
label='12-mo MA (pred)', zorder=3)
# Shade anomalous months
for d in share_s.index[anom_aligned]:
ax.axvspan(d, d + pd.offsets.MonthEnd(1),
color='red', alpha=0.15, zorder=1)
# Scatter anomaly points
anom_share = share_s[anom_aligned]
if len(anom_share) > 0:
ax.scatter(anom_share.index, anom_share.values * 100,
color='red', zorder=5, s=30,
label=f'Anomaly (n={n_anom})')
ax.set_title(pname, fontsize=9, pad=4)
ax.set_ylabel('Share (%)', fontsize=8)
ax.yaxis.set_major_formatter(mtick.FormatStrFormatter('%.1f%%'))
ax.tick_params(labelsize=7)
ax.legend(fontsize=7, loc='upper right')
for idx in range(n, len(axes_flat)):
axes_flat[idx].set_visible(False)
if save_path:
plt.savefig(save_path, bbox_inches='tight', dpi=150)
plt.show()
plot_anomaly_country('UKR', save_path=_DIR / 'fig_anomaly_ukr.png')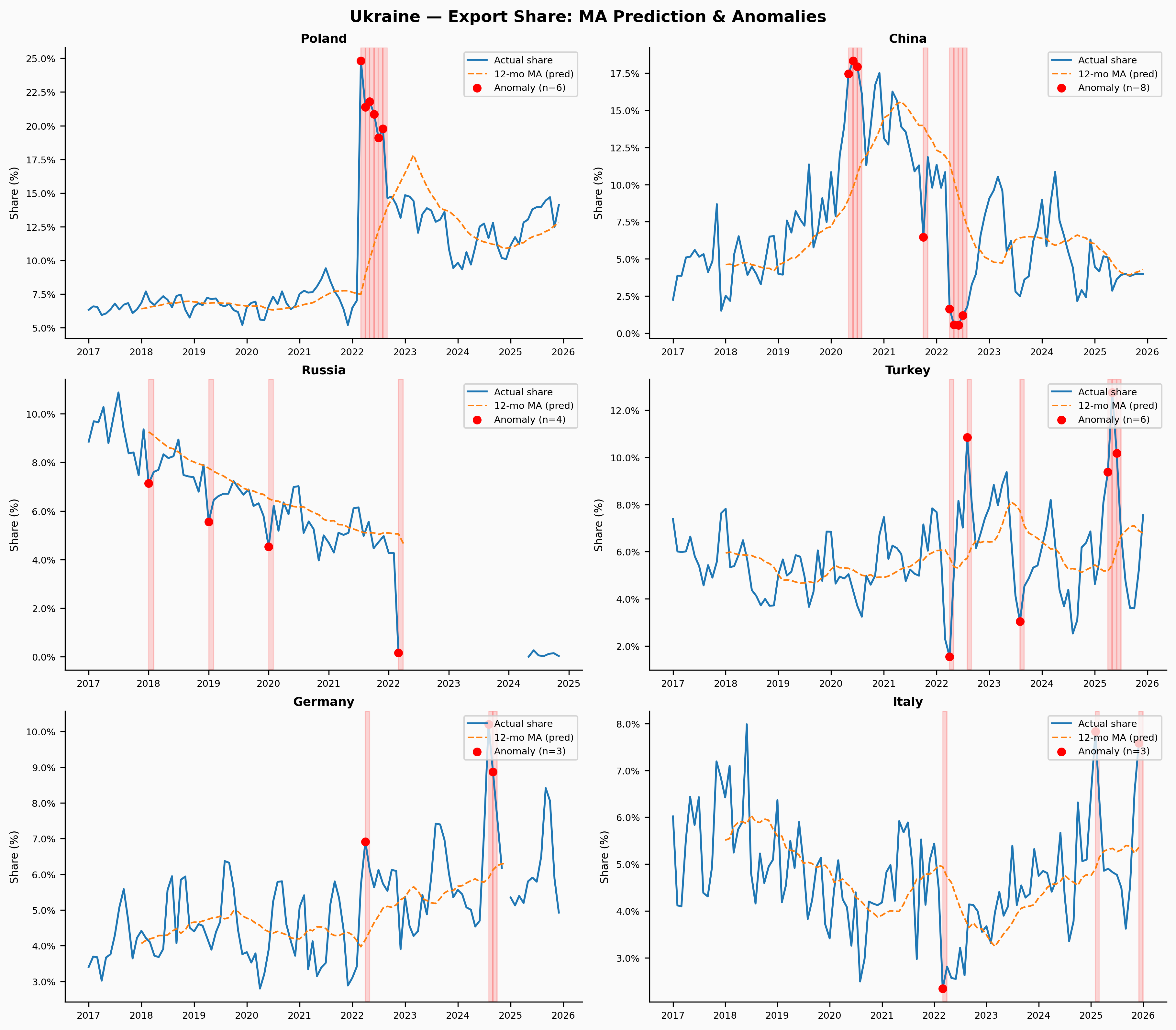
Venezuela
Venezuela’s story plays out differently — the disruption is slower, more economic than military. The hyperinflation crisis from 2017–2019 and the deepening US sanctions reshaped trade relationships gradually. The model flags extended anomaly periods for the US and India relationships, and the Spain series shows sustained misprediction as those flows collapsed.
Show code
plot_anomaly_country('VEN', save_path=_DIR / 'fig_anomaly_ven.png')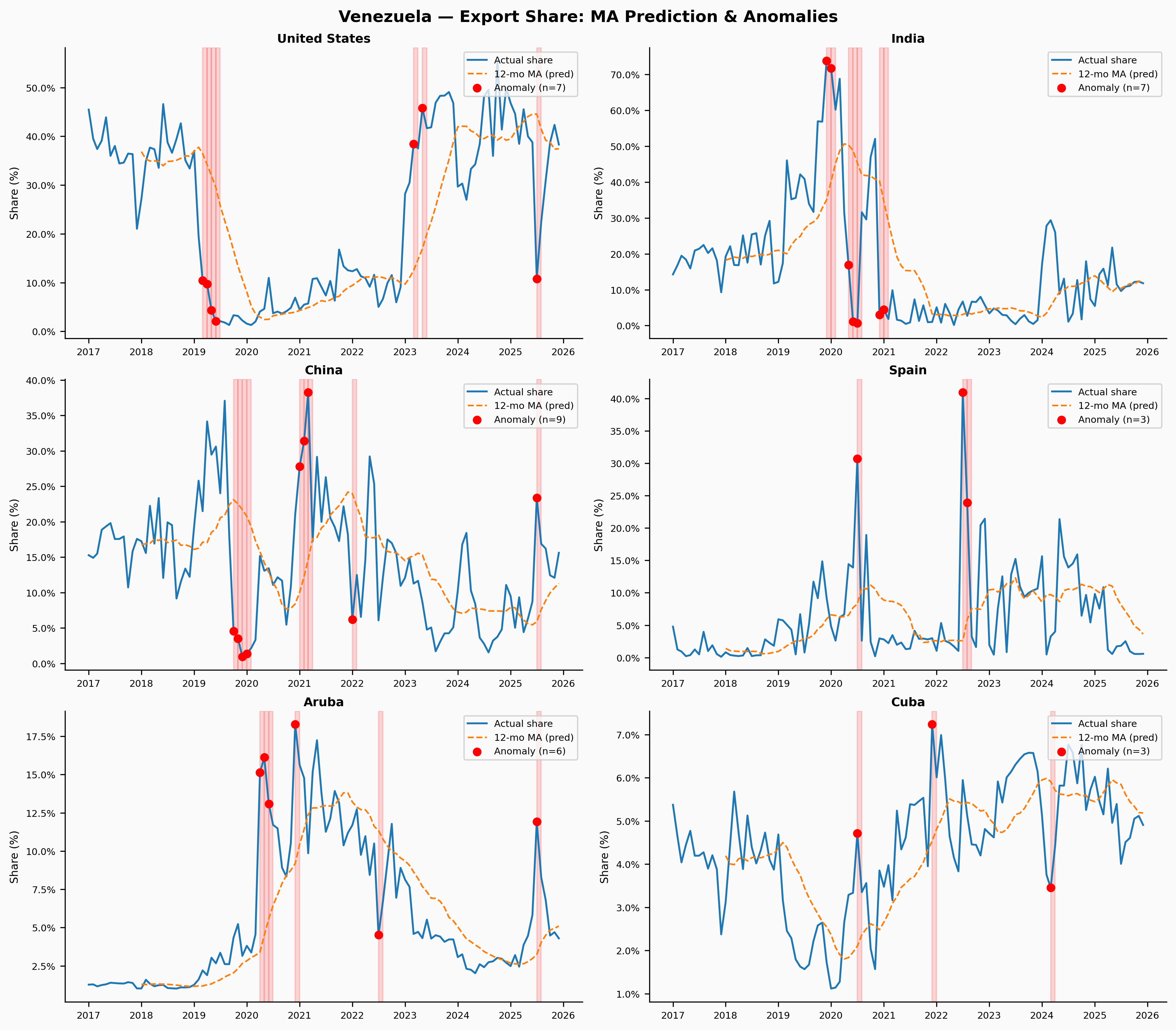
Yemen
Yemen is the hardest case — sparse data, small volumes, and a civil war that has made reliable reporting nearly impossible. The flagged anomalies are numerous but hard to interpret: they’re as likely to be data quality issues or one-off humanitarian shipments as genuine structural signals. This is a useful reminder that anomaly detection is only as good as the underlying data.
Show code
plot_anomaly_country('YEM', save_path=_DIR / 'fig_anomaly_yem.png')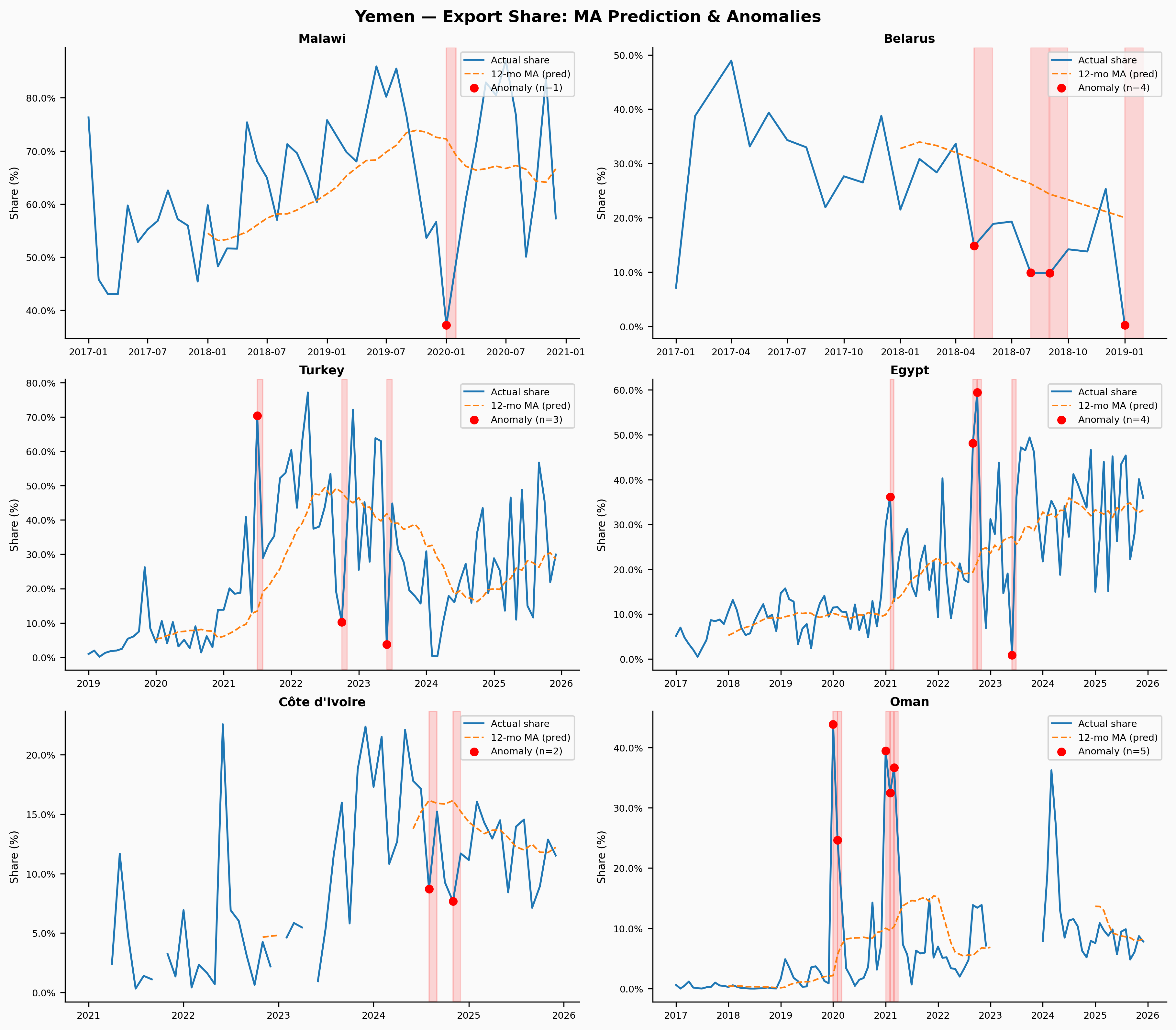
Mexico
Mexico shows what a clean, predictable series looks like. The US relationship is so dominant and so stable that even the moving average tracks it almost perfectly. The few flagged months tend to cluster around 2020 (COVID-era disruptions) and the 2022–2023 near-shoring surge. This is actually the most useful output from the model — because the baseline fit is good, the flagged anomalies carry real information.
Show code
plot_anomaly_country('MEX', save_path=_DIR / 'fig_anomaly_mex.png')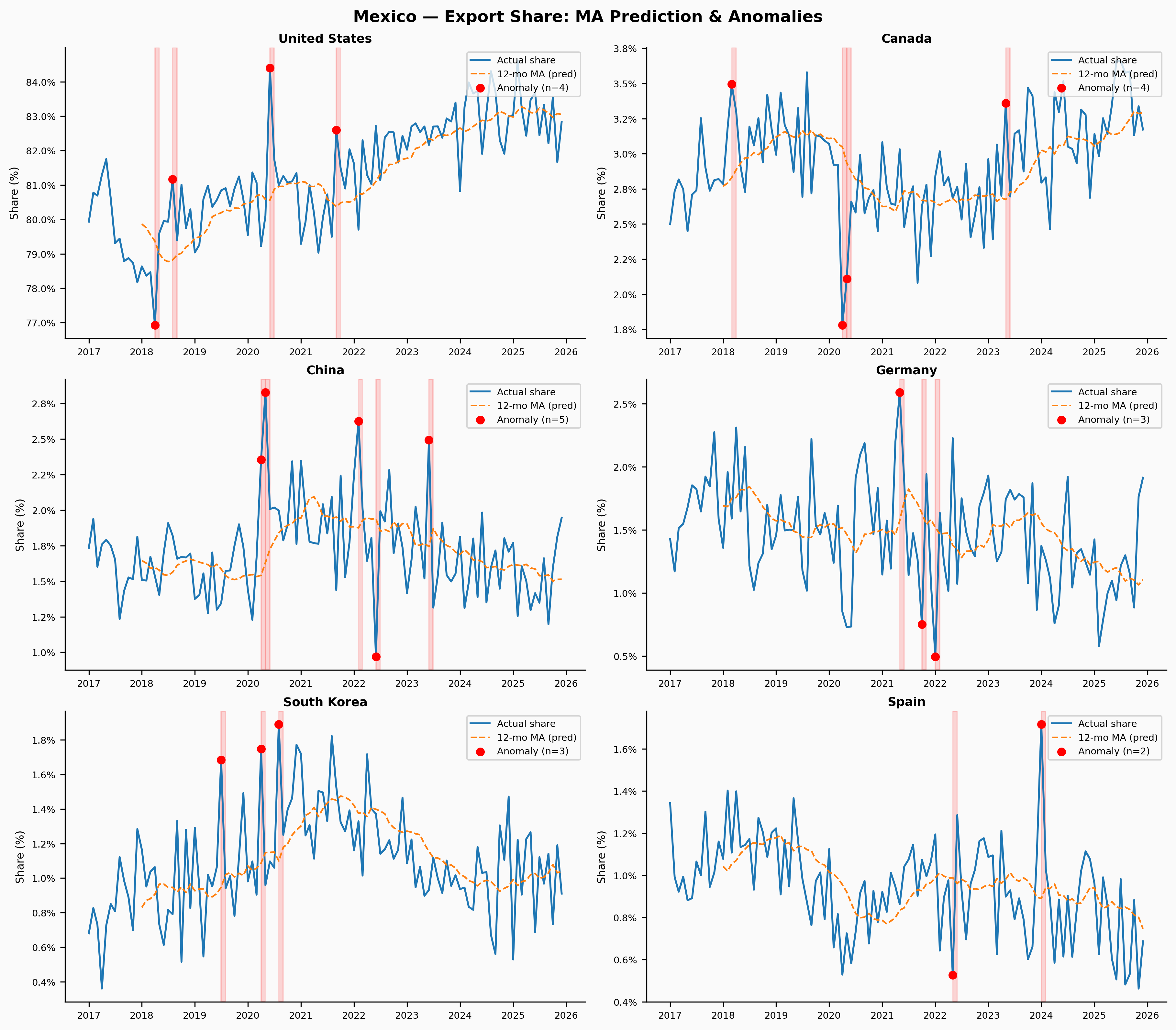
Denmark
Denmark is our control — a small, stable, high-income exporter with diversified trading relationships that change slowly. The MA model does well here by construction. The few flagged anomalies are worth examining in future work, but they’re likely to be either seasonal artefacts or one-off reporting quirks rather than structural breaks.
Show code
plot_anomaly_country('DNK', save_path=_DIR / 'fig_anomaly_dnk.png')
# Save preview
import shutil
shutil.copy(_DIR / 'fig_anomaly_ukr.png', _DIR / 'preview.png')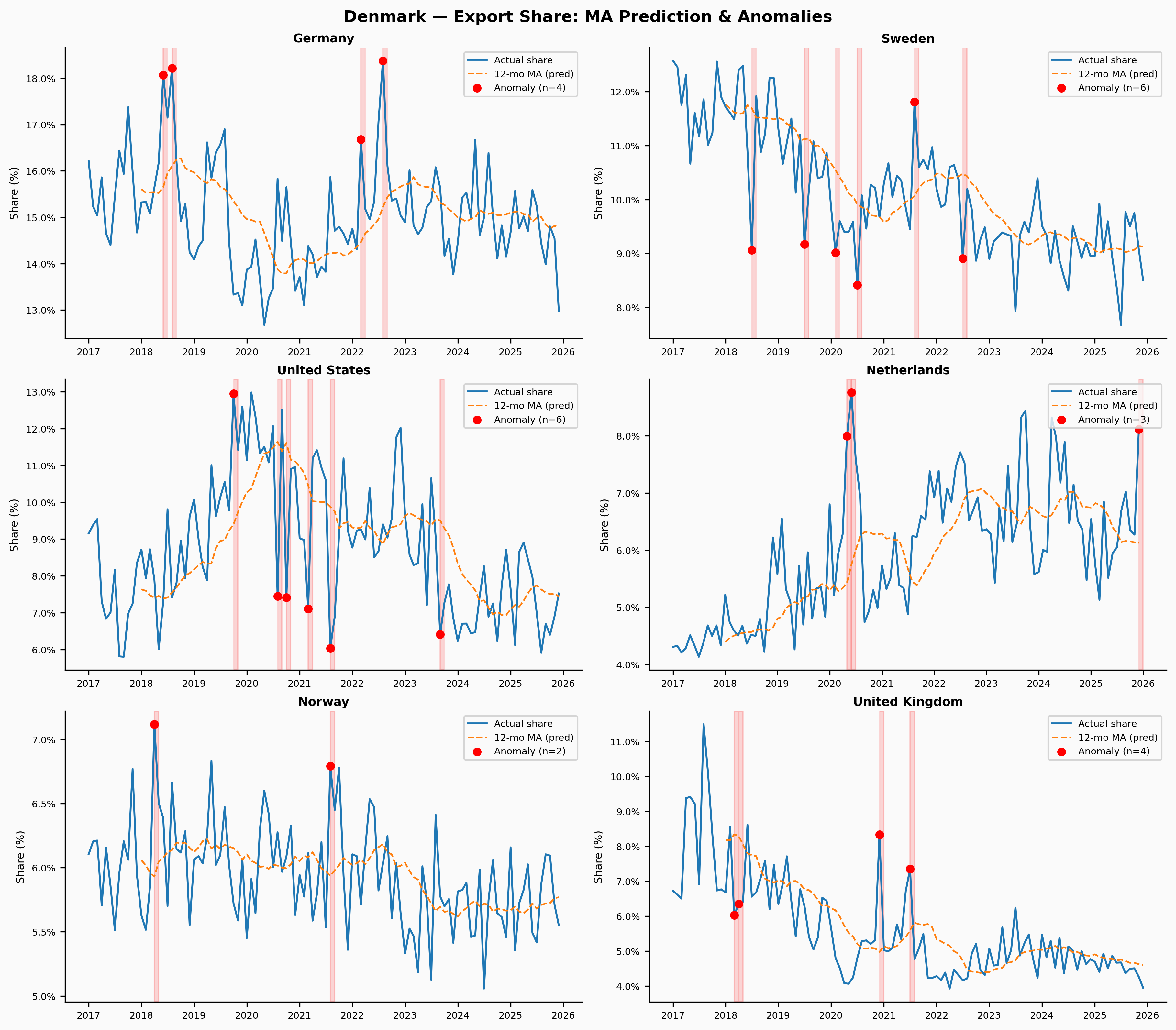
WindowsPath('preview.png')What the moving average gets wrong
A 12-month moving average is a bad forecasting model in three specific ways, each of which shows up in the residuals:
It can’t follow trends. Wherever a partner’s share is steadily changing — China’s growing share of Ukraine’s exports post-2022, the US share of Venezuelan exports declining year after year — the MA will consistently lag. Those systematic errors accumulate into residuals that are correlated over time, not independent. A proper model would need to explicitly model trend as a separate component.
It treats seasonality as signal. If a country’s exports to one partner spike every December (say, for commodity shipments ahead of winter), the 12-month MA smooths that pattern away and then flags December every year as anomalous. The anomaly detector is picking up the calendar, not the economy. A better approach would separate out seasonal patterns before looking at residuals — which is exactly what STL decomposition does.
It flags structural breaks persistently. After a genuine shock — like the 2022 invasion — the MA spends 12 months slowly incorporating the new level while flagging every intervening month as anomalous. This is the correct behavior in one sense (something really did change), but it’s not very useful analytically. You’d want to know when the break happened and what the new normal looks like, not just that things were weird for a year.
The high RMSE for Yemen and Venezuela isn’t primarily the model’s fault — those series are inherently noisy. But for Ukraine and Mexico, the model’s failures are clearly structural.
What’s next
Part 2 will replace the moving average with something that can handle these three problems: seasonal-trend decomposition (specifically, STL). The idea is to separate each series into a trend component, a seasonal component, and a residual before doing any anomaly detection. By only looking at the residual component, we remove the model’s susceptibility to calendar effects and smooth trends.
The hypothesis is that the anomalies flagged by a good model will be both fewer and more interpretable — concentrated in genuine structural breaks rather than distributed across every seasonal peak. Ukraine’s 2022 anomalies should still show up; Denmark’s shouldn’t.
We’ll also add a proper evaluation framework: for countries with known event dates (the Ukraine invasion in February 2022, Venezuela sanctions in 2019), we can measure whether the anomaly detector actually identifies the right months.
Data: IMF International Merchandise Trade Statistics, bulk flat file download. All code in this post runs without scipy or pycountry — only pandas, numpy, matplotlib, and Python’s standard math module.